6 Vergleich von Mittelwerten
Dass die Sonne morgen aufgehen wird, ist eine Hypothese; und das heisst: wir wissen nicht, ob sie aufgehen wird.
— Ludwig Wittgenstein (Tractatus logico-philosophicus, 6.36311)
6.1 Lernziele
Identifiziere Daten als gepaart bzw. verbunden, wenn zu jeder Beobachtungseinheit zwei Messungen der gleichen Variable vorliegen. Beispiele sind Prä-Post-Messungen (Messwiederholungen) bei einer Interventionsstudie oder die Preise für ein Buch in verschiedenen Buchhandlungen.
Berechne bei gepaarten Daten stets die Differenz zwischen den Datenpaaren (paarweise Differenzen). Dies ist die Prüfgrösse, mit der anschliessend statistische Tests durchgeführt werden können.
Identifiziere Daten als unabhängig, wenn die Werte einer Stichprobe keine Informationen über die Werte der anderen Stichprobe enthalten. Dies ist z.B. bei kontrollierten Studien der Fall, bei denen Daten von Interventions- und Kontrollgruppen miteinander verglichen werden: Die Daten der Interventionsgruppe sind unabhängig von den Daten der Kontrollgruppe und enthalten keine Information über die Kontrollgruppe.
Beachte, dass beim Vergleich der Differenz von zwei Parametern, die Interpretation von Konfidenzintervallen stets eine vergleichende Aussage beinhaltet; erwähne, welche Gruppe den grösseren Parameterwert hat.
Verwerfe die Nullhypothese, wenn ein Konfidenzintervall für eine Differenz zwischen zwei Parametern den Wert 0 enthält.
Verwende nichtparametrische Testverfahren, wenn der Stichprobenumfang klein ist (n < 30, Ausnahme gepaarter t-Test möglich ab n > 12) und/oder Hinweise vorliegen, dass die Populationsdaten nicht normal verteilt sind.
Gehe bei Hypothesentests stets systematisch vor:
- Lege die Prüfgrösse und das Signifikanzniveau fest, formuliere die Hypothesen und berechne die Kennzahlen.
- Prüfe die Voraussetzungen (1) Unabhängigkeit der Daten, (2) Normalverteilung der Prüfgrösse und wähle je nach Ergebnis den richtigen Test aus.
- Berechne das Konfidenzintervall für die Prüfgrösse.
- Berechne die Teststatistik t (t-Test), W (Wilcoxon-Vorzeichen-Test) oder U (Mann-Whitney-U-Test) und den p-Wert.
- Formuliere eine Schlussfolgerung in leicht verständlicher Sprache.
6.2 T-Tests
T-Tests sind die klassischen Hypothesentests. Sie gehören zur Gruppe der sog. parametrischen Tests. Damit parametrische Tests durchgeführt werden können, müssen die Daten in der Population annähernd normalverteilt sein. Wenn diese Voraussetzung nicht erfüllt ist, können alternativ nicht-parametrische Tests verwendet werden. Sie werden auch als verteilungsfreie Tests bezeichnet, da sie keine Annahme über die Verteilung der Daten voraussetzen. Nichtparametrische Tests sind in mehr Situationen zulässig als parametrische Tests.
Warum sollen wir dann überhaupt parametrische Tests einsetzen? Parametrische Tests haben eine grössere Teststärke (Power) als nicht-parametrische Tests. Mit anderen Worten: Wenn tatsächlich ein Effekt in der Population vorliegt, haben parametrische Tests bessere Chancen, diesen Effekt auch nachzuweisen. Zudem prüfen nicht-parametrische Tests typischerweise eine etwas andere Nullhypothese als die parametrischen Tests.
Im Zweifel gilt deshalb: Wenn wir keine Evidenz dagegen haben, dass unsere Daten aus einer normalverteilten Population stammen, verwenden wir einen parametrischen Test. Wenn die Verteilung der Daten aber den Voraussetzungen eines parametrischen Tests widerspricht, weichen wir auf nichtparametrische Tests aus.
Nichtparametrische Testverfahren werden am Ende dieses Kapitels vorgestellt.
6.3 T-Verteilung versus Normalverteilung
Wie am Ende des Kapitels zu den Wahrscheinlichkeitsverteilungen beschrieben, verwenden Statistikprogramme für die Berechnung der Teststatistik die t-Verteilung und nicht die Normalverteilung, um Wahrscheinlichkeiten für Ereignisse zu bestimmen. Der Grund dafür ist u.a., dass die t-Verteilung für kleinere Stichproben (n < 30) zuverlässigere Resultate liefert. Alles was wir zur Interpretation von z-Werten gelernt haben, gilt auch für t-Werte: Wie die z-Werte zeigen auch die t-Werte, um wieviel Standardfehler die Stichprobenkennzahl vom Populationsparameter entfernt ist.
6.4 T-Test für eine einfache Stichprobe
(Im folgenden Beispiel wird auch die Berechnung von Konfidenzintervallen für t-verteilte Daten besprochen. Der eigentliche T-Test ist der letzte Schritt 4.)
Beispiel: Werden Volksläufer über die Jahre eher schneller oder langsamer? Für die Bearbeitung diese Frage liegen die Daten des Cherryblossom-Volkslaufs, der jeweils im Frühjahr in Washington, DC durchgeführt wird, vor. Die Laufstrecke ist 16.1 km (10 Meilen) lang www.cherryblossom.org.
Die durchschnittliche Laufzeit für alle Läufer:innen, die den Lauf 2006 beendet haben betrug 93.29 Minuten. Zum Vergleich liegt uns eine Zufallsstichprobe von 100 Läufer:innen vor, die am Lauf im Jahre 2012 teilgenommen haben (die Teilnehmerzahl betrug im Jahr 2012 16’924 Läufer:innen). Uns interessiert, ob die Läufer:innen zwischen 2006 und 2012 im Durchschnitt schneller oder langsamer geworden sind.
Falls Sie die folgenden Schritte nachvollziehen wollen, finden Sie die Daten in 07_run12_100.csv.
6.4.1 Vorgehen
1. Hypothesen formulieren
Der Vergleichswert aus dem Jahr 2006 ist in diesem Fall der sog. Nullwert: \(\mu_0 = 93.29\).
\(H_0: \mu_{2012} = 93.29\), es gibt keinen Unterschied in der durchschnittlichen Laufzeit zwischen 2006 und 2012.
\(H_A: \mu_{2012} \neq 93.39\), es gibt einen Unterschied in der durchschnittlichen Laufzeit zwischen 2006 und 2012.
Ist das eine einseitige oder eine zweiseitige \(H_A\)?
Das Signifikanzniveau legen wir auf \(\alpha = 0.05\) fest.
2. Test-Voraussetzungen prüfen
- Wir bestimmen Mittelwert und Standardabweichung und erstellen ein Histogramm für die Laufzeit.
| n | m | s | Median |
|---|---|---|---|
| 100 | 95.87 | 16.66 | 95.01 |
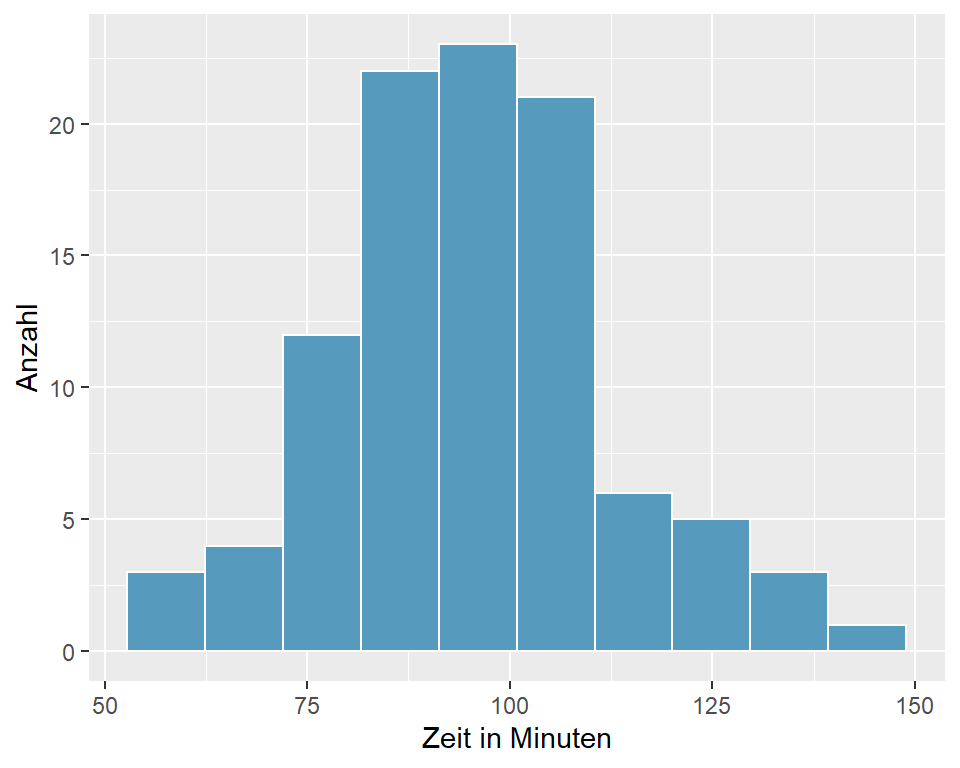
Abbildung 6.1: Cherryblossom-Run 2012: Laufzeiten für die Stichprobe n = 100
- Unabhängigkeit: Eine Zufallsstichprobe von 100 aus 16924 ist kleiner als 10%, die Beobachtungseinheiten sind unabhängig.
- Die Verteilung der Daten im Histogramm ist nahezu normal (evtl. etwas linkssteil). Mit welchen Verfahren könnten Sie zusätzlich auf Normalverteilung prüfen?
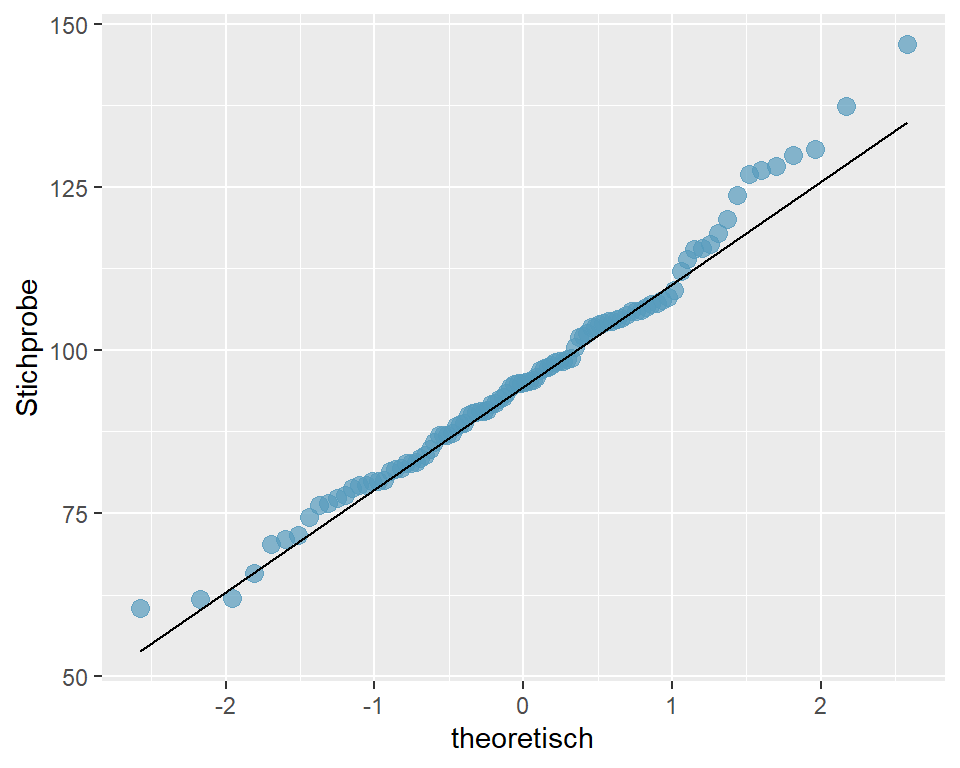
Abbildung 6.2: QQ-Plot fpr Cherryblossom-Run 2012, n = 100
3. Berechnung des 95%-Konfidenzintervalls für \(\bar{x}\)
\[SE = \frac{s}{\sqrt{n}} = \frac{16.66}{\sqrt{100}}=1.66\]
\[CI_{95} = \bar{x} \pm t_{1-\frac{\alpha}{2}, df} \times SE\]
Wir verwenden hier für die Berechnung des 95%-Konfidenzintervalls den t-Wert für die Anzahl Freiheitsgrade df = (100 - 1) = 99. Am einfachsten finden Sie den t-Wert mit dem Internet-Rechner Students T-Verteilung.
Die Berechnung in R/jamovi:
### R-Code
# die Funktion qt() berechnet eine Quantile für eine bestimmte Fläche und
# einen bestimmten Freiheitsgrad df
qt(.975, df = 99)## [1] 1.984217### R-Code
n <- 100 # Stichprobenumfang
m <- 95.87 # Mittelwert
s <- 16.66 # Standardabweichung
SE <- s/sqrt(n) # Standardfehler berechnen
t <- qt(.975, df = 100-1) # t-Wert für 95%-CI und df = n-1 berechnen
CI95 <- m + c(-1, 1) * t * SE # Grenzen für 95%-CI berechnen
round(CI95, 2) # 95%-CI gerundet auf 2 Nachkommastellen ausgeben## [1] 92.56 99.18Das 95%-Konfidenzintervall für die durchschnittliche Laufzeit 2012 ist [92.56; 99.18]. Es beinhaltet den Durchschnittswert von 2006 von 93.29 Minuten und wir haben keine Evidenz gegen die Nullhypothese.
4. Berechnung des p-Werts: Ein-Stichproben-T-Test
Die Berechnung des t-Werts erfolgt gleich wie für den z-Wert:
\[t = \frac{\bar{x} - \mu_0}{SE}\]
### R-Code
n <- 100 # Stichprobenumfang der Stichprobe 2012
m <- 95.87 # Stichprobenmittelwert 2012
s <- 16.66 # Standardabweichung 2012
mu <- 93.29 # Nullwert 2006
SE <- s/sqrt(n) # Standardfehler für den Stichprobenmittelwert 2012
t_wert <- (m - mu)/SE # Berechnung des t-Werts
round(t_wert, 3) # t-wert auf drei Stellen runden und ausgeben## [1] 1.549Die Teststatistik für unsere Punktschätzung ist \(t = 1.549\). Den p-Wert können wir wieder mit dem Internet-Rechner Students T-Verteilung oder mit R/jamovi berechnen.
### R-Code
p_wert <- 2 * (1-pt(t_wert, df = 99)) # p-Wert für eine zweiseitige Hypothese
p_wert <- round(p_wert, 3) # p-Wert auf 3 Nachkommastellen runden
p_wert # p-Wert anzeigen## [1] 0.125Ein \(p\)-Wert von \(p\) = 0.125 bedeutet, dass unter der Annahme, dass \(H_0\) wahr ist, ein Ergebnis wie in unserer Stichprobe oder ein noch extremeres Ergebnis mit einer Wahrscheinlichkeit von 12.5 % vorkommt. \(p\) = 0.12 ist grösser als unser Signifikanzniveau \(\alpha\) = 0.05 und wir verwerfen die \(H_0\) nicht.
5. Schlussfolgerung formulieren
Untersucht wurde die Frage, ob sich die durchschnittliche Laufzeit von Volksläufer:innen über die Jahre geändert hat. Als Nullwert wurde die durchschnittliche Laufzeit von 2006 von 93.29 Minuten angenommen. In einer Zufallsstichprobe n = 100 der Läufer:innen am Cherryblossom Run 2012 betrug die durchschnittliche Laufzeit 95.87 [92.56, 99.18] Minuten, \(t(99)\) = 1.549, \(p\) = 0.125. Die vorliegenden Daten liefern keine Evidenz dafür, dass sich die durchschnittlichen Laufzeiten zwischen 2006 und 2012 verändert haben.
6.4.2 Konfidenzintervall für einen Mittelwert Schritt-für-Schritt:
- Vorbereitung: Berechne den \(\bar{x}\), \(s\) und \(n\) und lege das Konfidenzniveau fest (üblicherweise 95% = 0.95)
- Voraussetzungen: Prüfe, ob die Voraussetzungen erfüllt sind, dass die Daten aus einer Normalverteilung stammen (QQ-Plot).
- Berechnung: Wenn die Voraussetzungen erfüllt sind, berechne SE und finde \(t_{df}\), um die Grenzen des Konfidenzintervalls zu berechnen.
- Schlussfolgerung: Interpretiere das Konfidenzintervall im Zusammenhang mit der Fragestellung.
Code-Tipp: \(t_{df}\) lässt sich in R/jamovi einfach berechnen:
### R-Code
# Copy-Paste in R-Konsole: für df muss jeweils n - 1 eingetragen werden
# für ein 95%-Konfidenzintervall
qt(.975, df)
# für ein 99%-Konfidenzintervall
qt(.995, df)
# für ein 90%-Konfidenzintervall
qt(.95, df)6.4.3 Ein-Stichproben-T-Test Schritt-für-Schritt:
- Vorbereitung: Identifiziere den für die Frage relevanten Parameter (die Prüfgrösse), formuliere die Hypothesen, lege das Signifikanzniveau \(\alpha\) fest und berechne \(\bar{x}\), \(s\) und \(n\).
- Voraussetzungen: Prüfe, ob die Voraussetzungen erfüllt sind, dass die Daten aus einer normalverteilten Population stammen (QQ-Plot).
- Wenn die Voraussetzungen erfüllt sind, berechne SE, den \(t_{df}\)-Wert und den p-Wert.
- Schlussfolgerung: Beurteile den Hypothesentest, indem du den \(p\)-Wert mit dem Signifkanzniveau \(\alpha\) vergleichst. Formuliere eine Schlussfolgerung im Zusammenhang mit der Fragestellung in leicht verständlicher Sprache.
Code-Tipp: Der \(p\)-Wert lässt sich in R/jamovi einfach berechnen:
### R-Code
# p-Wert für eine zweiseitige Hypothese berechnen
2 * (1 - pt(t_wert, df = n - 1)) # df = n - 1 = Stichprobenumfang - 16.4.4 R/jamovi
R-Code und Output
### R-Code
t.test(x = sample$time, # sample$time = daten$variable
mu = 93.29, # mu = Nullwert
alternative = "two.sided") # zweiseitige Alternativhypothese##
## One Sample t-test
##
## data: sample$time
## t = 1.5489, df = 99, p-value = 0.1246
## alternative hypothesis: true mean is not equal to 93.29
## 95 percent confidence interval:
## 92.56457 99.17743
## sample estimates:
## mean of x
## 95.871jamovi-Output
jamovi\..\T-Tests\One Sample T-Test
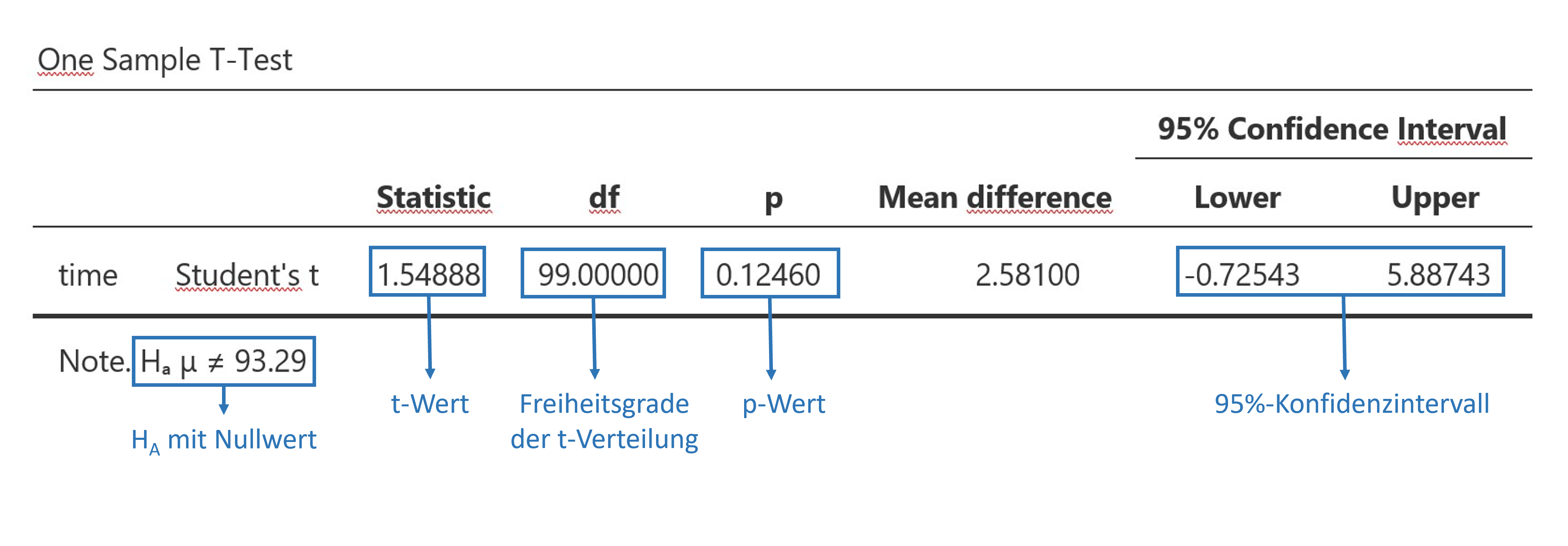
jamovi-Output One Sample T-Test
6.5 T-Test für verbundene Stichproben
Von verbundenen bzw. gepaarten Daten sprechen wir dann, wenn zwei Variablen voneinander abhängig sind: Dies bedeutet, dass die Werte der einen Messung die Werte der anderen Messung beeinflussen. Das ist der Fall, wenn wir z.B. die Preise für ein Buch in verschiedenen Läden vergleichen oder wenn wir Messungen bei Individuen zu verschiedenen Zeitpunkten, z.B. vor und nach einer Intervention (Prä-Post-Messungen), durchführen.
Beispiel: In einer Studie wird untersucht, ob die Testpersonen mit einem neuen Schlafmittel länger schlafen als ohne Schlafmittel. Die Studie wird mit 20 Personen durchgeführt. Zuerst wird die Schlafdauer ohne Medikament (Baseline-Messung), dann die Schlafdauer mit Medikament (Follow-Up-Messung) gemessen.
Falls Sie die folgenden Schritte nachvollziehen wollen, finden Sie die Daten in 07_schlafmittel.csv.
Die Tabelle zeigt die Daten zu den ersten vier Probanden:
| Proband | ohne_Med | mit_Med |
|---|---|---|
| 1 | 5.28 | 5.83 |
| 2 | 5.69 | 4.69 |
| 3 | 4.81 | 4.43 |
| 4 | 5.90 | 6.49 |
Jedem Probanden entsprechen zwei Messungen (Variablen): Eine für die Schlafdauer ohne und eine für die Schlafdauer mit Medikament. In diesem Fall liegen gepaarte Daten vor, da für jede Beobachtungseinheit zwei Messzeitpunkte vorliegen, die miteinander verglichen werden.
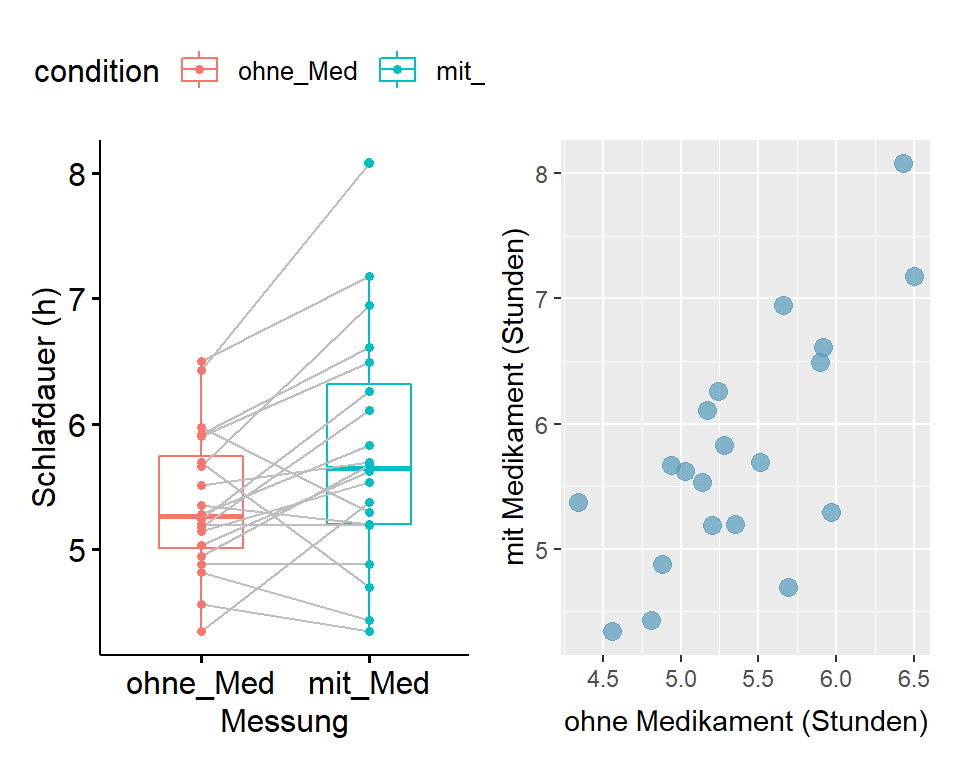
Abbildung 6.3: Zusammenhang zwischen Schlafdauer mit und ohne Medikament
Das Streudiagramm zeigt, dass die Schlafdauer mit Medikament in einem Zusammenhang mit der Schlafdauer ohne Medikament steht: Probanden, die ohne Medikament länger schlafen, schlafen auch mit Medikament länger.
Wenn wir den Effekt einer Intervention bei gepaarten Daten untersuchen, ist die Prüfgrösse die Differenz der Datenpaare, die sog. paarweisen Differenzen. Im vorliegenden Beispiel ist dies die Differenz zwischen der Schlafdauer mit und ohne Medikament. Wenn die Differenzen bei der Datenerhebung noch nicht berechnet wurden, erstellt man eine neue abgeleitete Variable und berechnet für jeden Probanden die paarweisen Differenzen. Dabei ist es wichtig eine konsistente Ordnung einzuhalten: Wenn wir uns für den Effekt des Medikamentes interessieren, berechnen wir die paarweisen Differenzen durch Subtraktion der Schlafdauer ohne Medikament von der Schlafdauer mit Medikament.
\[paarweise.Differenz = Schlafdauer.mit.Medi - Schlafdauer.ohne.Medi\] Wenn das Medikament einen positiven Effekt auf die Schlafdauer hat, erhalten wir eine positive Differenz, wenn das Medikament die Schlafdauer verkürzt, erhalten wir eine negative Differenz. Für die Durchführung des T-Tests für gepaarte Daten verwenden wir als Prüfgrösse den Mittelwert der paarweisen Differenzen. Der Mittelwert der paarweisen Differenzen ist das Mass für den Effekt des Medikaments.
Die Prüfgrösse bei gepaarten Daten ist der Mittelwert der paarweisen Differenzen \(\mu_{d}\).
| Proband | ohne_Med | mit_Med | paarweise.Differenzen |
|---|---|---|---|
| 1 | 5.28 | 5.83 | 0.55 |
| 2 | 5.69 | 4.69 | -1.00 |
| 3 | 4.81 | 4.43 | -0.38 |
| 4 | 5.90 | 6.49 | 0.59 |
Mit dem Mittelwert für paarweise Differenzen als Prüfgrösse haben wir die gleiche Situation, wie beim Einstichproben-T-Test, nämlich einen Mittelwert, den wir gegen einen Nullwert vergleichen, und das weitere Vorgehen ist wie beim Einstichproben-T-Test.
6.5.1 Vorgehen
1. Hypothesen formulieren
Prüfgrösse definieren: Mittelwert der paarweisen Differenzen = \(\bar{x}_{d}\)
Hypothesen formulieren
- \(H_0: \mu_{d} = 0\), es gibt keinen Unterschied, die Differenzen ergeben 0
- \(H_A: \mu_{d} \neq 0\), es gibt einen Unterschied, die Differenzen ergeben nicht 0
- \(H_0: \mu_{d} = 0\), es gibt keinen Unterschied, die Differenzen ergeben 0
Signifikanzniveau \(\alpha\) festlegen, üblicherweise \(\alpha = 0.05\)
\(\bar{x}\), \(s\) und \(n\) berechnen
| Variable | n | m | s |
|---|---|---|---|
| paarweise.Differenzen | 20 | 0.395 | 0.672 |
| ohne_Med | 20 | 5.376 | 0.574 |
| mit_Med | 20 | 5.771 | 0.953 |
2. Test Voraussetzungen prüfen:
- Prüfe, ob die Voraussetzungen erfüllt sind, dass \(\bar{x}_{d}\) aus einer annähernd normal verteilten Population stammt.
- Prüfung auf Unabhängigkeit: Es handelt sich um eine Zufallsstichprobe, n < 10% der Population
- Prüfung der Prüfgrösse (= paarweise Differenzen!) auf Normalverteilung (QQ-Plot unten)
- Stichprobenumfang: Wenn die Prüfgrösse paarweise Differenzen sind, kann der T-Test ab n > 12 angewendet werden, wenn die Daten annähernd normalverteilt sind. Ab n > 100 ist der T-Test nahezu unbeschränkt durchführbar, unabhängig von der zugrundeliegenden Verteilung.
- Prüfung auf Unabhängigkeit: Es handelt sich um eine Zufallsstichprobe, n < 10% der Population
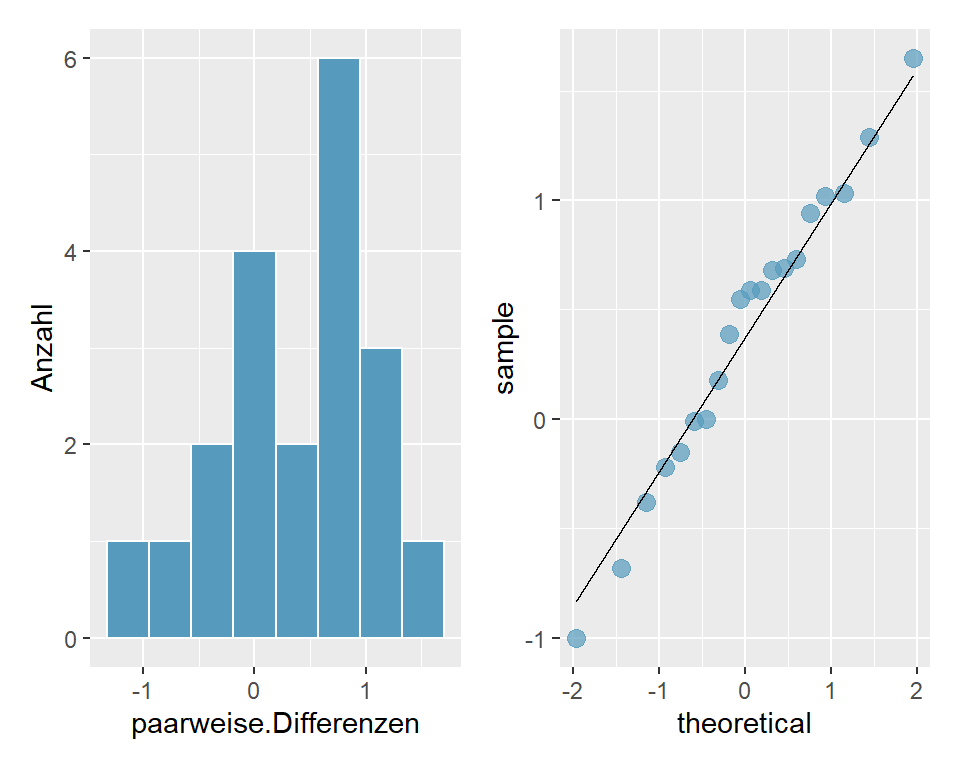
Abbildung 6.4: Histogramm und QQ-Plot für paarweise Differenzen
Im Histogramm sind die Daten leicht linksschief verteilt. Im QQ-Plot liegen die Punkte weitgehend auf einer Linie. Daher entscheiden wir für normalverteilte Daten.
3. SE, \(t_{df}\)-Wert p-Wert und 95%-Konfidenzintervall berechnen.
\[SE = \frac{0.672}{\sqrt{20}} = 0.15\]
\[t_{df=19} = \frac{0.395-0}{0.150} = 2.629\]
Den p-Wert für t und df = 20-1 können wir wieder mit dem Internet-Rechner Students T-Verteilung oder mit R/jamovi berechnen.
### R-Code
2 * (1-pt(t, df = 20-1)) # p-Wert für zweiseitige Hypothese, t-Verteilung, df = 19Mit \(p\) = 0.017 ist die Wahrscheinlichkeit für den beobachteten Effekt oder einen stärkeren Effekt kleiner als unser Signifkanzniveau \(\alpha = 0.05\) und wir haben Evidenz dafür, dass wir die Nullhypothese zugunsten der Alternativhypothese verwerfen können.
\[CI_{95} = \bar{x} \pm t_{1-\frac{\alpha}{2}, df} \times SE = 0.395 \pm 2.093 \times 0.15\]
### R-Code
# 95%-Konfidenzintervall: Quantile für t = 0.975 und df = 20- 1
qt(.975, 19) ## [1] 2.093024### R-Code
# p-Wert und 95%-CI berechnen
n <- 20
s <- .672
m <- .395
SE <- s/sqrt(n)
t <- (.395 - 0)/SE
p_wert <- 2 * (1-pt(t, df = 20-1))
p_out <- paste("p-Wert =", round(p_wert, 3))
CI95 <- m + c(-1, 1) * qt(.975, 19) * SE
CI95 <- round(CI95, 3)
CI95_out <- paste("[", CI95[1], ", ", CI95[2], "]", sep = "")
# Output
p_out## [1] "p-Wert = 0.017"CI95_out## [1] "[0.08, 0.71]"Die Berechnung ergibt ein 95%-Konfidenzintervall für den Mittelwert der Differenz in der Schlafdauer von 0.395 [0.08, 0.71] Stunden. Das 95%-Konfidenzintervall enthält den Nullwert nicht und wir verwerfen die Nullhypothese zugunsten der Alternativhypothese.
4. Schlussfolgerung formulieren
Untersucht wurde der Einfluss eines Medikaments auf die Schlafdauer bei 20 Probanden. Das Medikament hat die Schlafdauer durchschnittlich um 0.395 [0.08 0.71] Stunden signifikant verlängert, \(t(19)\) = 2.629, \(p\) = 0.017.
6.5.2 R/jamovi
R Code und Output
### R-Code
# Variante 1: Als T-Test für gepaarte Stichproben
t.test(x = medi_data$mit_Med, # Baseline-Data
y = medi_data$ohne_Med, # Follow-Up-Data
paired = TRUE, # gepaarte Daten
alternative = "two.sided") # zweiseitige Alternativhypothese##
## Paired t-test
##
## data: medi_data$mit_Med and medi_data$ohne_Med
## t = 2.6237, df = 19, p-value = 0.01672
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.07978913 0.70921087
## sample estimates:
## mean of the differences
## 0.3945# Variante 2: Als Einstichproben-T-Test mit der Variable paarweise.Differenzen
t.test(x = medi_data$paarweise.Differenzen,
mu = 0,
alternative = "two.sided")##
## One Sample t-test
##
## data: medi_data$paarweise.Differenzen
## t = 2.6237, df = 19, p-value = 0.01672
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 0.07978913 0.70921087
## sample estimates:
## mean of x
## 0.3945Der T-Test für gepaarte Stichproben berechnet zuerst die paarweisen Differenzen und ermittelt anschliessend die Teststatistik. Wenn man die paarweisen Differenzen im Datensatz berechnet hat, kann der Einstichproben-T-Test durchgeführt werden. Beide Varianten kommen zum exakt gleichen Ergebnis.
jamovi-Output
Wähle jamovi\..\T-Tests\Paired Samples T-Test

jamovi-Output Paired Samples T-Test
6.6 Zweistichproben-T-Test für unabhängige Stichproben
In diesem Abschnitt beschäftigen wir uns mit der Differenz von zwei Populationsmittelwerten \(\mu_1 - \mu_2\) unter der Voraussetzung, dass die Daten nicht gepaart, also unabhängig, sind. Typisch sind Vergleiche zwischen zwei Gruppen bzw. Stichproben, z.B. kontrollierte Studien in denen Interventionsgruppe und Kontrollgruppe verglichen werden oder der Vergleich des Gewichts von Neugeborenen von rauchenden und nicht-rauchenden Müttern.
Die Formeln in diesem Abschnitt werden etwas komplizierter. In der Regel lassen wir die Software die Berechnungen durchführen und müssen nicht mit ihnen arbeiten. Sie stehen hier als Hintergrundinformation und für diejenigen, die von Hand rechnen wollen.
6.6.1 Konfidenzintervall für einen Mittelwertsunterschied
Im Folgenden werden zuerst die theoretischen Grundlagen erarbeitet, anschliessend folgt ein Schritt-für-Schritt Beispiel für die Durchführung des Zweistichproben-T-Tests für unabhängige Stichproben.
Beispiel: Hat die Behandlung mit embryonalen Stammzellen (ESC) einen Effekt auf die Pumpfunktion des Herzens nach einem Herzinfarkt? (Die Daten sind im Datensatz 07_stemcell.csv abgelegt)
Die folgende Tabelle enthält die Kennzahlen aus einem Experiment, bei dem der Effekt von ESC bei Schafen, die einen Herzinfarkt erlitten hatten, geprüft wurde. Jedes dieser Schafe wurde randomisiert der Gruppe ESC oder der Kontrollgruppe zugewiesen, dann wurde ihre Herzkapazität (Auswurffraktion) gemessen. Details zur Studie hier The Lancet. Ein positiver Wert entspricht einer Steigerung der Auswurffraktion, was einer besseren Erholung entspricht. Unsere erste Aufgabe ist es, das 95%-Konfidenzintervall für den Effekt der ESCs auf die Herzfunktion im Vergleich zur Kontrollgruppe zu berechnen.
Codebook: Datensatz stemcell.csv
| Variable | Beschreibung |
|---|---|
| trtm | Behandlung: ctrl = Kontrolle, esc= embryonale Stammzellen |
| before | Baseline: Auswurffraktion vor der Behandlung |
| after | Follow-Up: Auswurffraktion nach der Behandlung |
| trmt | before | after |
|---|---|---|
| ctrl | 35.25 | 29.50 |
| ctrl | 36.50 | 29.50 |
| ctrl | 39.75 | 36.25 |
| ctrl | 39.75 | 38.00 |
| ctrl | 41.75 | 37.50 |
| ctrl | 45.00 | 42.75 |
| ctrl | 47.00 | 39.00 |
| ctrl | 52.00 | 45.25 |
| ctrl | 52.00 | 52.25 |
| esc | 29.00 | 31.00 |
| esc | 29.50 | 43.75 |
| esc | 34.00 | 36.00 |
| esc | 35.00 | 41.50 |
| esc | 35.25 | 39.50 |
| esc | 42.50 | 40.00 |
| esc | 44.00 | 45.75 |
| esc | 49.25 | 55.25 |
| esc | 53.75 | 51.00 |
Nach dem Erstellen einer abgeleiteten Variable Differenz = after - before berechnen wir die Kennzahlen für den Effekt der Behandlung.
| trmt | n | m | s |
|---|---|---|---|
| ctrl | 9 | -4.33 | 2.76 |
| esc | 9 | 3.50 | 5.17 |
Die Kennzahlen zeigen, dass die Auswurffraktion in der Kontrollgruppe CTRL um durchschnittlich -4.33% abgenommen und in der Interventionsgruppe ESC um 3.5% zugenommen hat.
Die Prüfgrösse bei unabhängigen Daten ist die Differenz der Mittelwerte \(\mu_1 - \mu_2\). Die Prüfgrösse für die Differenz in der Herzleistung zwischen ESC- und Kontrollgruppe lässt sich berechnen als
\[\bar{x}_{esc} - \bar{x}_{ctrl} = 3.5 - (-4.33) = 7.83\]
Für die Prüfung, ob wir für diese Differenz die t-Verteilung anwenden können, müssen wir die bisher verwendeten Voraussetzungen etwas erweitern:
Unabhängigkeit: Die Daten müssen sowohl zwischen den Stichproben als auch innerhalb der Stichproben unabhängig sein. Dies wird dadurch sichergestellt, dass die Beobachtungseinheiten randomisiert aus der Population ausgewählt und randomisiert den Gruppen Intervention oder Kontrolle zugeteilt werden.
Normalverteilung: Die Daten müssen in beiden Stichproben normalverteilt sein.
Die Berechnung des Standardfehlers \(SE\) und der Anzahl Freiheitsgrade \(df\) ist in diesem Fall etwas komplizierter und wird normalerweise von der Statistiksoftware übernommen. Diejenigen, die von Hand rechnen wollen, können diese - etwas vereinfachte - Formel verwenden:
\[SE_{\bar{x}_2-\bar{x1}_1} = \sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}\]
beziehungsweise, bei unbekanntem \(\sigma\)
\[SE_{\bar{x}_2 - \bar{x}_1} = \sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}} = SE_{x_1} + SE_{x_2}\]
Als Freiheitsgrad df für die t-Verteilung verwenden wir
\[df = n_1 + n_2 - 2\]
Prüfung der Voraussetzungen
- Unabhängigkeit ist gegeben, da die Schafe randomisiert ausgewählt und den Gruppen Intervention oder Kontrolle zugeordnet wurden.
- Prüfung der Normalverteilung anhand von Histogramm und QQ-Plot: Wir entscheiden für normalverteilte Daten.
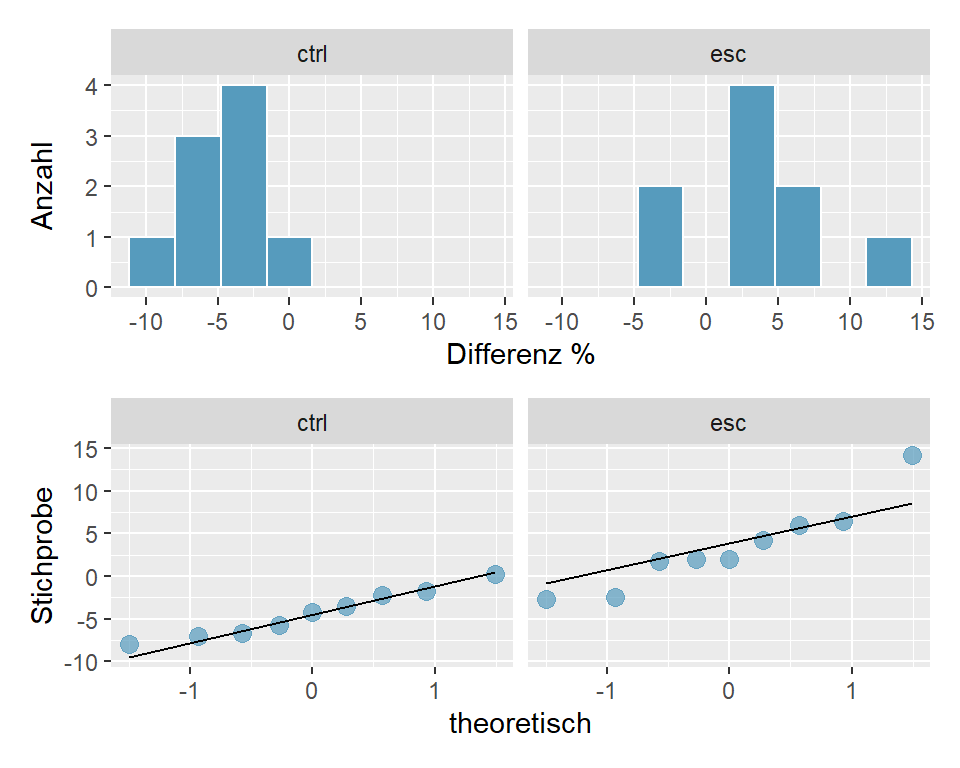
Abbildung 6.5: Histogramm und QQ-Plot für ESC- und Kontrollgruppe
Für die Berechnung des Standardfehlers verwenden wir die Standardabweichung der Stichprobe, da wir die Standardabweichung der Population nicht kennen:
\[SE = \sqrt{\frac{s_{esc}^2}{n_{esc}} + \frac{s_{ctrl}^2}{n_{ctrl}}} = \sqrt{\frac{5.17^2}{9} + \frac{2.76^2}{9}} = 1.95\]
Die Anzahl Freiheitsgrade \(df\) der \(t\)-Verteilung ist \((n_1 + n_2 - 2) = (8 + 8 - 2) = 14\)
Den kritischen \(t\)-Wert für eine \(t\)-Verteilung mit \(df\) = 8 für ein 95%-Konfidenzintervall erhalten wir in `R``
### R-Code
# t-Wert für ein 95%-Konfidenzintervall mit df = 8
qt(.975, 14) ## [1] 2.144787Durch Einsetzen können wir jetzt das 95%-Konfidenzintervall für die Differenz des Effekts zwischen den beiden Stichproben berechnen:
\[CI_{95} = 7.83 \pm 2.145 \times 1.95 = [3.33; 12.33]\]
Das 95%-Konfidenzintervall beinhaltet Null nicht und wir haben Evidenz für einen signifikanten Effekt.
Schlussfolgerung: Die Behandlung mit embryonalen Stammzellen bei Schafen, die einen Herzinfarkt erlitten haben, verbessert die Pumpfunktion des Herzens signifikant im Durchschnitt um 7.83% [3.647%, 12.013%] im Vergleich zu keiner Behandlung.
6.6.2 Der Zweistichproben-T-Test für unabhängige Stichproben Schritt-für-Schritt
Für einen T-Test für einen Mittelwertsunterschied ist eine der Voraussetzungen, dass der Stichprobenumfang \(n\) gleich oder grösser als 30 ist. Dies ist für das Beispiel mit den Schafen nicht gegeben und wir verwenden ein neues Beispiel.
Frage: Hat es einen Einfluss auf das Geburtsgewicht von Neugeborenen, wenn schwangere Frauen rauchen? Wir prüfen diese Frage anhand eines Datensatzes, der eine Zufallsstichprobe von 150 Müttern und ihren Neugeborenen umfasst. Die Variable smoke erfasst, ob die Mutter während der Schwangerschaft geraucht hat oder nicht und die Variable weightgibt das Geburtsgewicht in g an. Die Raucherinnengruppe umfasst 50 Mütter, die Nichtraucherinnengruppe 100 Mütter. (Die Daten sind im Datensatz 07_geburtsgewicht_g.csv abgelegt.)
Die Tabelle gibt die ersten 5 Einträge im Datensatz an:
| f_age | m_age | weeks | premature | visits | gained | weight | sex_baby | smoke |
|---|---|---|---|---|---|---|---|---|
| 31 | 30 | 39 | full term | 13 | 1 | 3121 | male | smoker |
| 30 | 28 | 39 | full term | 13 | 0 | 3402 | female | nonsmoker |
| 43 | 31 | 41 | full term | 5 | 20 | 3202 | female | smoker |
| 36 | 35 | 40 | full term | 12 | 29 | 4028 | male | nonsmoker |
| 33 | 27 | 41 | full term | 15 | 38 | 3175 | male | smoker |
Das Vorgehen für die statistische Analyse ist wie bisher:
- Vorbereitung: Identifiziere den für die Frage relevanten Parameter (die Prüfgrösse), formuliere die Hypothesen und lege das Signifikanzniveau \(\alpha\) fest.
- Prüfe, ob die Voraussetzungen (Unabhängigkeit der Daten, Normalverteilung) erfüllt sind.
- Wenn die Voraussetzungen erfüllt sind, berechne \(SE\), das 95%-Konfidenzintervall, den \(t_{df}\)-Wert und den \(p\)-Wert.
- Schlussfolgerung: Beurteile den Hypothesentest, indem du den \(p\)-Wert mit dem Signifkanzniveau \(\alpha\) vergleichst. Formuliere eine Schlussfolgerung im Zusammenhang mit der Fragestellung in leicht verständlicher Sprache.
1. Hypothesen formulieren
- Die Prüfgrösse ist \(\mu_s - \mu_{ns}\) (\(s\) = smoker, \(ns\) = nonsmoker)
- Signifikanzniveau \(\alpha = 0.05\)
Hypothesen:
- \(H_0: \mu_s = \mu_{ns}\), der Raucherstatus hat keinen Einfluss auf das Geburtsgewicht von Neugeboren.
- \(H_A: \mu_s \neq \mu_{ns}\), der Raucherstatus hat einen Einfluss auf das Geburtsgewicht von Neugeboren.
2. Voraussetzungen prüfen
- Es handelt sich um eine Zufallsstichprobe, die Daten sind unabhängig.
- Histogramm und QQ-Plot zeigen eine linksschiefe Verteilung für beide Gruppen. Aus Übungsgründen entscheiden wir jedoch, dass die Daten normalverteilt sind.
- Der Stichprobenumfang in jeder Gruppe ist n > 30.
- Die Streuung der Daten ist in beiden Stichproben gleich. Wir gehen immer davon aus, dass die Streuung der Daten nicht gleich ist und führen grundsätzlich den Welch’s-Test durch, der eine Anpassung des Zweistichproben-T-Tests für ungleiche Varianzen ist.
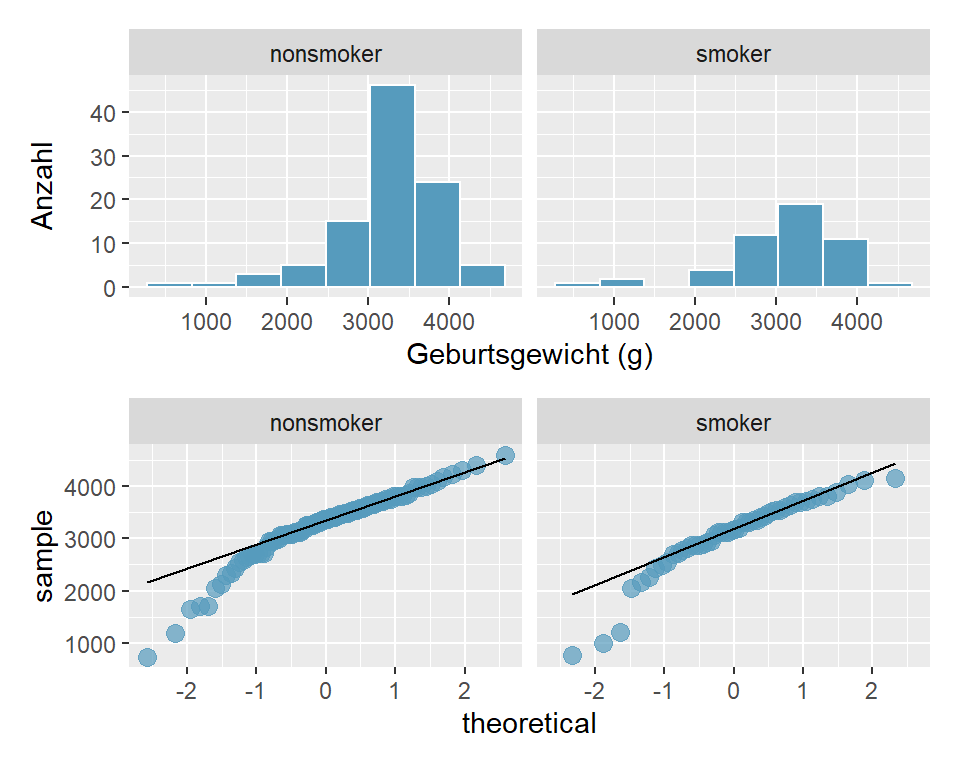
Abbildung 6.6: Histogramm und QQ-Plot für Geburtsgewicht nach Raucherstatus der Mutter
Berechnungen von Kennzahlen, SE, t-Wert und p-Wert
| smoke | n | m | s |
|---|---|---|---|
| nonsmoker | 100 | 3256.6 | 650.53 |
| smoker | 50 | 3075.0 | 724.61 |
Neugeborene von nicht-rauchenden Müttern sind im Durchschnitt \(3256.6 - 3075.0 = 181.6g\) schwerer als von rauchenden Müttern.
Berechnung des Standardfehlers SE der Prüfgrösse:
\[SE = \sqrt{\frac{s_{ns}^2}{n_{ns}} + \frac{s_s^2}{n_s}} = \sqrt{\frac{651^2}{100} + \frac{725^2}{50}} = 121.4\]
Berechnung des 95%-Konfidenzintervalls
Kritischer t-Wert
### R-Code
qt(.975, df = 148)## [1] 1.976122\[CI_{95} = 181.6 \pm 1.976 \times 121.4 = [-62.4; 425.6]\]
Neugeborene von Nichtraucherinnen sind im Durchschnitt um 181.6 [-58.286; 421.486] schwerer als Neugeborene von Raucherinnen. Das 95%-Konfidenzintervall beinhaltet Null, d.h. kein Unterschied im Geburtsgewicht ist ein plausibler Wert, und wir haben keine Evidenz gegen die Nullhypothese.
Berechnung des t-Werts:
\[t = \frac{181.6 - 0}{121.4} = 1.496\]
### R-Code
t <- (181.6 - 0)/121.4
t## [1] 1.495881Berechnung des \(p\)-Werts:
Die Anzahl Freiheitsgrade \(df = n_{ns} + n_{s} - 2 = 100 + 50 - 2 = 148\): Wir können den p-Wert für \(t\) wieder in einer Tabelle nachschlagen oder mit R/jamoviberechnen:
### R-Code
2 * (1 - pt(1.496, df = 148)) # p-Wert für eine zweiseitige Hypothese und df = 148## [1] 0.136783\(p = 0.137\); Dieser \(p\)-Wert ist grösser als \(\alpha = 0.05\) und wir haben keine ausreichende Evidenz, um die Nullhypothese zu verwerfen.
Schlussfolgerung: Untersucht wurde die Frage, ob Neugeborene von rauchenden Müttern ein anderes Geburtsgewicht haben als Neugeborene von nichtrauchtenden Müttern. Anhand der vorliegenden Daten konnte kein signifikanter Unterschied für deas Geburtsgewicht von Neugeborenen rauchender und nichtrauchender Mütter festgestellt werden: Neugeborene von nichtrauchenden Müttern sind im Durchschnitt 181.6 [-58.286; 421.486] leichter als von nichtrauchenden Müttern, t(49) = 1.496, p = 0.137.
Anmerkung: Dies ist ein vergleichsweise kleiner Datensatz; grössere Datensätze in aktuellen Studien liefern Evidenz dafür, dass Neugeborene von rauchenden Müttern ein geringeres Geburtsgewicht aufweisen als von nichtrauchenden Müttern. In den 70er-Jahren hat die Tabak-Industrie diese Tatsache sogar als Werbung mit dem Argument benutzt, dass Mütter kleinere Babies bei der Geburt bevorzugen. (Reeves and Bernstein 2006)
6.6.3 R/jamovi
R Code und Output
### R-Code
t.test(
weight ~ smoke, data = births,
alternative = "two.sided", # Voreinstellung, muss nicht angegeben werden
paired = FALSE, # Voreinstellung, muss nicht angegeben werden
var.equal = FALSE # Voreinstellung, muss nicht angegeben werden
)##
## Welch Two Sample t-test
##
## data: weight by smoke
## t = 1.4961, df = 89.275, p-value = 0.1381
## alternative hypothesis: true difference in means between group nonsmoker and group smoker is not equal to 0
## 95 percent confidence interval:
## -59.56991 422.76991
## sample estimates:
## mean in group nonsmoker mean in group smoker
## 3256.6 3075.0R führt standardmässig einen Welch’s-Test durch.
jamovi-Output
jamovi\..\T-Tests\Independent Samples T-Test > Welch's
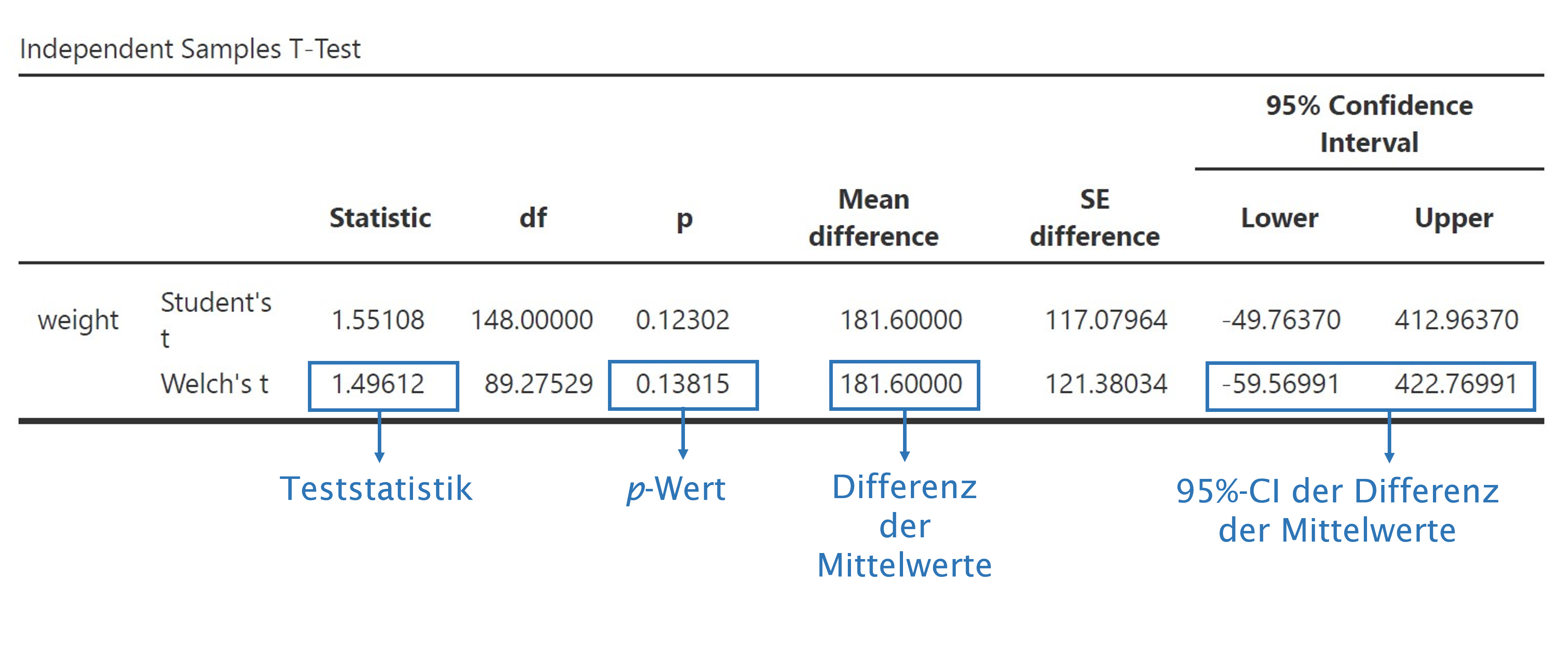
jamovi-Output Welch-Test
6.7 Nicht-parametrische Tests
Die bisher besprochenen Testverfahren (t-Tests) können nur durchgeführt werden, wenn gewisse Voraussetzungen erfüllt sind:
- Besonders bei kleineren Stichprobenumfängen müssen die Daten aus einer normalverteilten Population stammen. Wir kontrollieren das jeweils mittels Histogramm und QQ-Plot.
- Der minimale Stichprobenumfang bei gepaarten Daten sollte n > 12 und bei unabhängigen Daten n > 30 sein.
- Es handelt sich um quantitative Daten.
Es stellt sich nun die Frage, wie man Hypothesentests durchführt, wenn diese Bedingungen nicht erfüllt sind, wie im Beispiel der rauchenden Mütter und dem Geburtsgewicht ihrer Babies.
Ist die Verteilung der Daten nicht bekannt, so müssen andere Testverfahren, sog. nicht-parametrische Verfahren verwendet werden. Diese stellen keine Annahme bezüglich der Verteilung der Daten voraus und eignen sich daher besonders für kleine Stichproben, bei denen die Beurteilung von Normalitätstests oft mit einer grossen Unsicherheit verbunden ist. Ein weiterer Vorteil der nichtparametrischen Verfahren besteht darin, dass auch qualitativ-ordinalen Daten, z.B. VAS-Skalen oder Schulnoten, analysiert werden können.
6.7.1 Rang-Methoden (rank tests)
Rangtests spielen in der Klasse der nichtparametrischen Verfahren eine dominierende Rolle. Dabei ist die zu berechnende Teststatistik nur eine Funktion der rangierten (geordneten) Beobachtungen; die Beobachtungswerte selber werden nicht verwendet. Dies bedeutet, dass man nur die ordinale Information der Daten nutzt. Daher ist auch die Mindestanforderung an die Daten, dass sie qualitativ-ordinal skaliert sind.
Mathematisches Detail (nicht zu lernen): Die nichtparametrischen Methoden arbeiten mit diskreten Verteilungen. Die Berechnung von \(p\)-Werten erfolgt jedoch über eine sog. Approximation (Annäherung) an die Normalverteilung, welche eine kontinuierliche Verteilung ist. Bei der Aproximation einer diskreten an eine kontinuierliche Verteilung muss ein Korrekturfaktor Kontinuitätskorrektur (engl. continuity correction) eingeführt werden, der in der Ausgabe von Statistikprogrammen erwähnt wird.
6.7.2 Wilcoxon-Vorzeichenrangtest
jamovi\T-Tests\Paired Samples T-Test\Wilcoxon Rank
Der Wilcoxon-Vorzeichenrangtest wird für gepaarte Daten oder den Einstichprobenfall gewählt.
Beispiel: Wie Lange dauert eine Schwangerschaft? Und hängt die genaue Bestimmung von der Untersuchungsmethode ab? Zur Verfügung stehen zwei Methoden um die Schwangerschaftsdauer zu bestimmen: Einerseits die Methode der letzten Menstruationsperiode (LMP) und andererseits die Ultraschallmethode (US). Zufällig werden zehn schwangere Frauen ausgewählt und nach beiden Methoden die Schwangerschaftsdauer bestimmt. Die Untersuchung wird blindiert durchgeführt, so dass die LMP-Untersucher:innen die Ergebnisse der US-Untersucher:innen nicht kennen und umgekehrt. (Die Daten sind im Datensatz 07_schwangerschaft.csv abgelegt.)
Die Bestimmung der Schwangerschaftsdauer bei zehn schwangeren Frauen einer einfachen Stichprobe aus der gegebenen Population liefert folgende LMP und US Daten:
| ID | LMP | US | LMPminusUS |
|---|---|---|---|
| 1 | 275 | 273 | 2 |
| 2 | 292 | 285 | 7 |
| 3 | 281 | 270 | 11 |
| 4 | 284 | 272 | 12 |
| 5 | 285 | 278 | 7 |
| 6 | 283 | 276 | 7 |
| 7 | 290 | 291 | -1 |
| 8 | 294 | 290 | 4 |
| 9 | 300 | 279 | 21 |
| 10 | 284 | 292 | -8 |
Wie können wir diese Daten interpretieren?
Als erstes berechnen wir die Kennzahlen und erstellen Grafiken zum Vergleich der beiden Bestimmungsmethoden.
| name | m | Median | s |
|---|---|---|---|
| LMP | 286.8 | 284.5 | 7.2 |
| US | 280.6 | 278.5 | 8.3 |
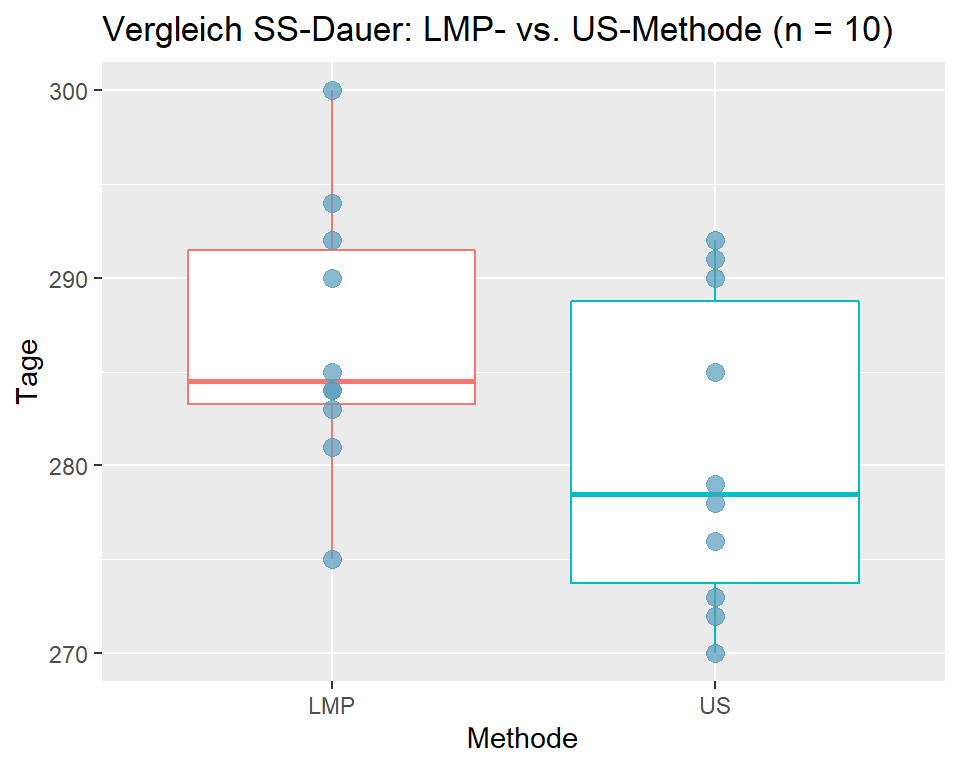
Abbildung 6.7: Boxplots für Schwangerschaftsdauer
Der Vergleich von Mittelwert und Median und die Boxplots zeigen, dass die Daten linkssteil verteilt sind. Zudem ist der Stichprobenumfang mit n = 10 klein. Die Voraussetzungen für einen t-Test für gepaarte Daten sind nicht gegeben.
Hypothesen:
\(H_0: Median_{LMP} = Median_{US}\), die LMP- und die US-Methode ergeben die gleiche Schwangerschaftsdauer.
\(H_A: Median_{LMP} \neq Median_{US}\), die LMP- und die US-Methode ergeben eine unterschiedliche Schwangerschaftsdauer.
Merke: Beim Wilcoxon-Vorzeichenrangtest vergleichen wir Mediane und nicht Mittelwerte!
Signifikanzniveau: \(\alpha = 0.05\)
Vorgehen Wilcoxon-Vorzeichenrangtest
Das Prinzip des Wilcoxon-Vorzeichen-Rangtests wird hier exemplarisch an einem Beispiel erläutert. Üblicherweise wird der Test in einem Statistikprogramm durchgeführt.
Gilt die Nullhypothese, so kann die Differenz der LMP- und US-Werte einer schwangeren Frau sowohl positiv wie auch negativ sein; weder positive noch negative Werte sollten überwiegen und die Differenzen sollten symmetrisch um Null verteilt sein. Der Wilcoxon-Vorzeichen-Rangtest prüft, ob die paarweisen Differenzen symmetrisch mit dem Median gleich Null verteilt sind.
Zur Durchführung des Tests werden diese Differenzen passend nach Rängen geordnet (rangiert). Es werden die absoluten Differenzen (Abstände zu Null) rangiert, ohne das Vorzeichen zu beachten. Ist eine Differenz Null, wird sie bei der Rangierung nicht verwendet und vom Stichprobenumfang n abgezogen.
| ID | LMP | US | LMPminusUS | Rang | Vorzeichen |
|---|---|---|---|---|---|
| 1 | 275 | 273 | 2 | 2 | plus |
| 2 | 292 | 285 | 7 | 5 | plus |
| 3 | 281 | 270 | 11 | 8 | plus |
| 4 | 284 | 272 | 12 | 9 | plus |
| 5 | 285 | 278 | 7 | 5 | plus |
| 6 | 283 | 276 | 7 | 5 | plus |
| 7 | 290 | 291 | -1 | 1 | minus |
| 8 | 294 | 290 | 4 | 3 | plus |
| 9 | 300 | 279 | 21 | 10 | plus |
| 10 | 284 | 292 | -8 | 7 | minus |
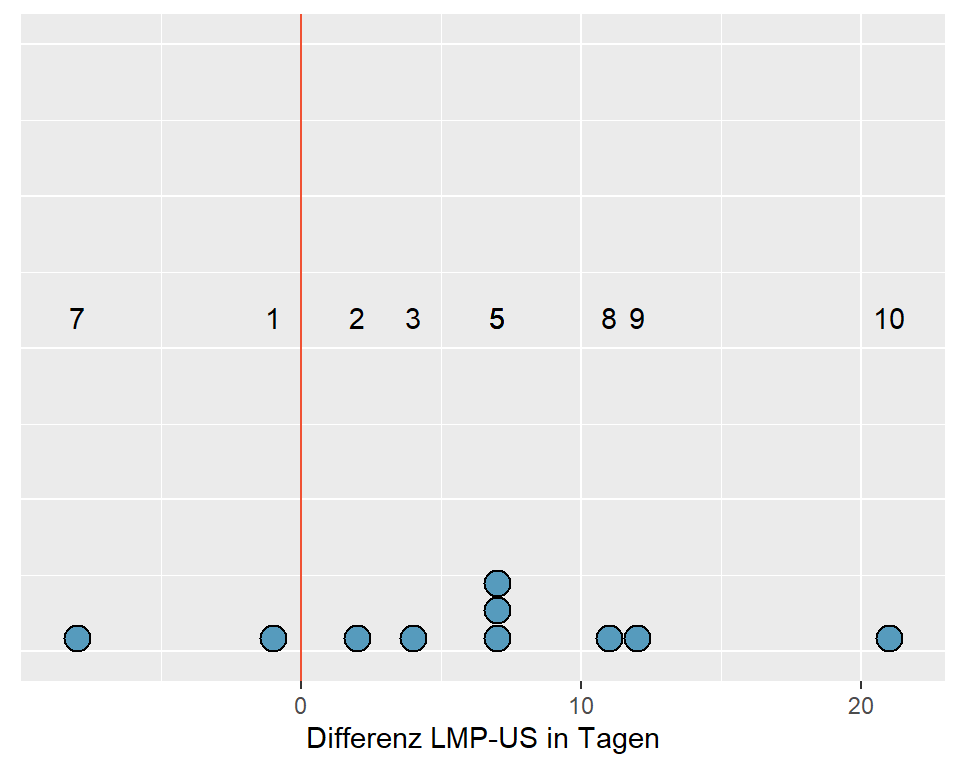
Abbildung 6.8: Punktediagramm der Schwangerschaftsdauer, US- und LMP-Werte mit Rängen
Wenn die Differenzen symmetrisch um Null angeordnet sind, haben wir Evidenz dafür, dass \(H_0\) wahr ist. Beachte, dass einige dieser Differenzen der Schwangerschaftsdauer gleich sind. Der Wert 7 kommt drei Mal vor. Diesen drei Werten sollten die Ränge 4, 5 und 6 zugeordnet werden. Ihr mittlerer Rang (Mittelwert von 4, 5 und 6) ist 5. Deshalb wird dieser mittlere Rang jedem der drei Werte zugeordnet.
Wir vergleichen jetzt die Summe der positiven Ränge mit der Summe der negativen Ränge. Sind diese beiden Rangsummen etwa gleich gross, haben wir keine Evidenz gegen die Nullhypothese, andernfalls werden wir die Nullhypothese ablehnen. Als einfache Teststatistik W verwenden wir Rangsumme der positiven Differenzen.
Summe der positiven Ränge: 2 + 3 + 5 + 5 + 5 + 8 + 9 + 10 = 47
Summe der negativen Ränge: 1 + 7 = 8
Teststatistik \(W\) (in R Teststatistik \(V\)) = 47
Berechnung des p-Werts für \(W = 47\) und \(n = 10\)
### R-Code
W <- 47
p_Wert <- 2 * psignrank(W, n = 10, lower.tail = FALSE)
round(p_Wert, 3) ## [1] 0.037Schlussfolgerung: In einer Stichprobe von n = 10 schwangeren Frauen wurde die Frage untersucht, wie lange eine Schwangerschaft dauert und ob die Untersuchungsmethoden US und LMP zum gleichen Ergebnis kommen. Die Methode US ergibt gegenüber der Methode LMP eine um durchschnittlich um 6.2 Tage kürzere Schwangerschaftsdauer, Wilcoxon-Vorzeichenrangtest W = 47, p = 0.037.
6.7.2.1 R/jamovi
R Code und Output
### R-Code
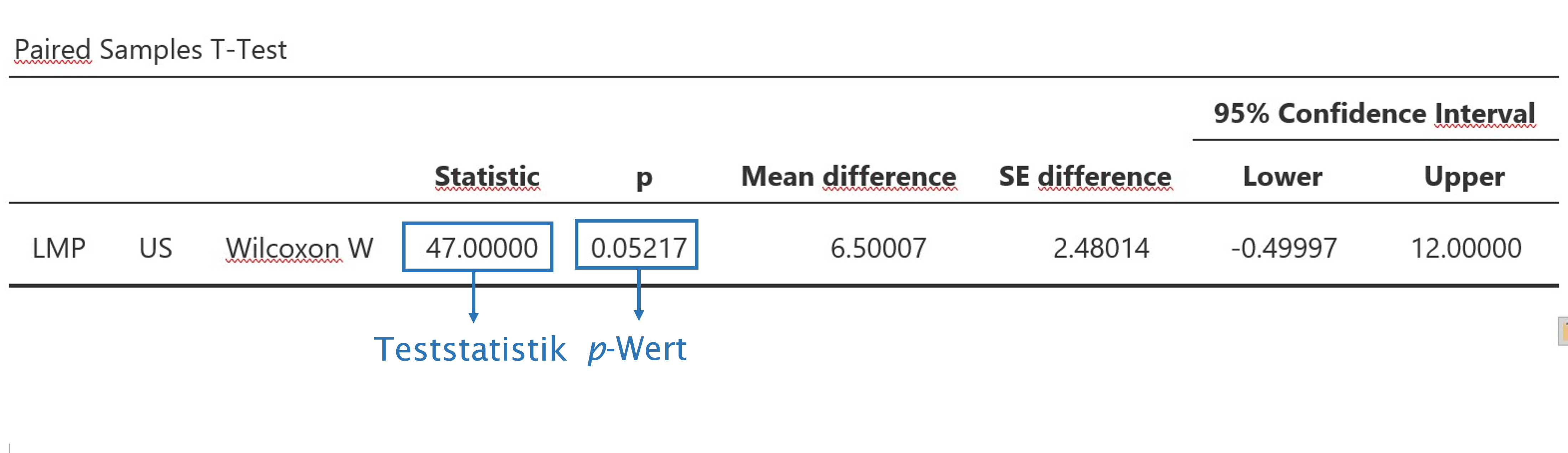
wilcox.test(ss$LMP, ss$US,
paired = TRUE,
alternative = "two.sided",
correct = TRUE) # mit Kontinuitätskorrektur##
## Wilcoxon signed rank test with continuity correction
##
## data: ss$LMP and ss$US
## V = 47, p-value = 0.05217
## alternative hypothesis: true location shift is not equal to 0Anmerkung:
- Bei der Berechnung in
Rkann entspricht die ausgegebene Teststatistik V \(W\).
- In
Rkann entschieden werden, ob die Kontinuitätskorrektur durchgeführt wird oder nicht. Bei unterschiedlichen Stichprobenumfängen sollte dies immer geschehen.jamoviführt die Kontinuitätskorrektur immer durch.
jamovi\..\T-Tests\Paired Samples T-Test > Wilcoxon Rank
jamovi-Output Wilcoxon Rank
6.7.3 Mann-Whitney-U-Test
Der Mann-Whitney-U-Test (= Wilcoxon-Rangsummentest) wird für den Vergleich von zwei Mittelwerten verwendet, wenn der Stichprobenumfang n < 30 ist oder wenn die Daten nicht normalverteilt sind.
Beispiel: Erreichen Studierende, die während einer Woche täglich 30 Minuten Statistikübungen machen, bessere Noten in einer Statistikprüfung? Für diese Studie wurden 15 Studierende zufällig ausgewählt und zufällig den Gruppen INT (n = 8) und CON (n = 7) zugeteilt. Beide Gruppen besuchten die Statistikvorlesung. Die Studierenden der Gruppe INT machten zusätzlich während einer Woche täglich 30 Min. Statistikübungen, die Gruppe CON machte keine Statistikübungen. Nach einer Woche wurde ein Statistiktest durchgeführt, der mit 0 bis 100 Punkten bewertet wurde. (Die Daten sind im Datensatz 07_statex.csv abgelegt)
| INT | CON |
|---|---|
| 89, 92, 94, 96, 91, 99, 84, 90 | 88, 93, 95, 75, 72, 80, 81 |
| Gruppe | n | m | Median | s |
|---|---|---|---|---|
| CON | 7 | 83.43 | 81.0 | 8.81 |
| INT | 8 | 91.88 | 91.5 | 4.58 |
Die deskriptive Analyse ergibt, dass die Interventionsgruppe im Durchschnitt 8.45 Punkte mehr erreicht als die Kontrollgruppe. Der Stichprobenumfang ist kleiner als 30 und die Daten sind leicht linkssteil verteilt; daher sind die Voraussetzungen für einen T-Test nicht erfüllt.
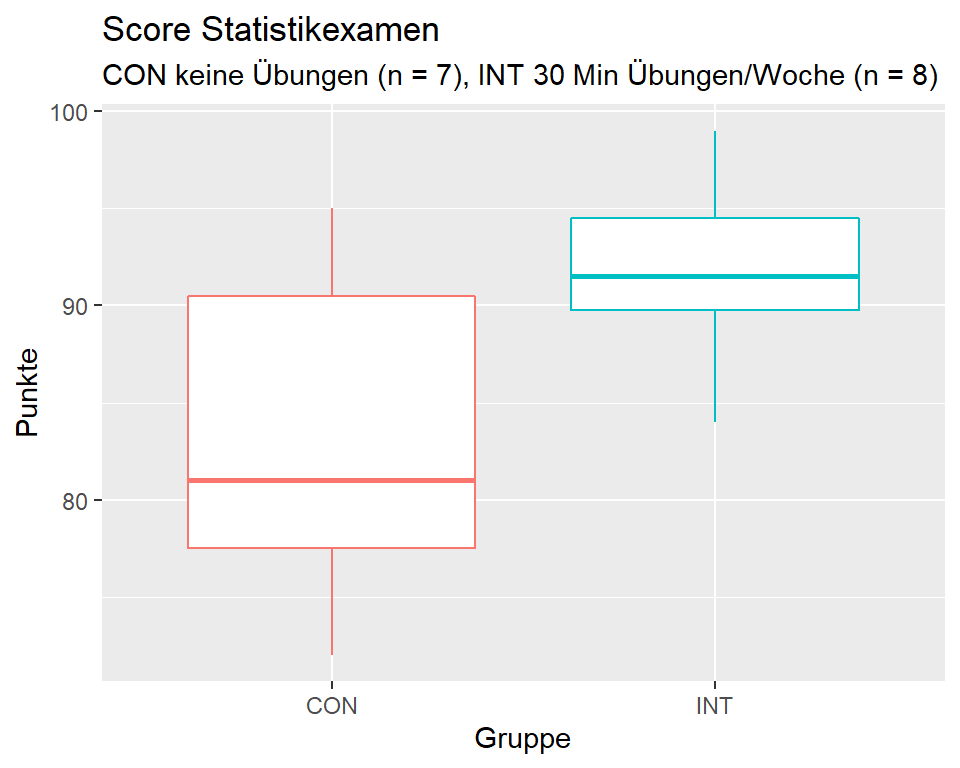
Abbildung 6.9: Boxplot für Statistikresultate
Hypothesen
\(H_0: P(INT > CON) = P(CON > INT)\), die Summen der Rangplätze von INT und CON unterscheiden sich nicht.
\(H_A: P(INT > CON) \neq P(CON > INT)\), die Summen der Rangplätze von INT und CON unterscheiden sich.
Signifikanzniveau \(\alpha = 0.05\)
Für den Mann-Whitney-U-Test berechnen wir die Teststatistik U. \(U\) ist der kleinere Wert von den beiden \(U_1\) und \(U_2\), die wie folgt berechnet werden:
\(U_1 = n_1 \times n_2+\frac{n_1 \times (n_1+1)}{2} - R_1\)
\(U_2 = n_1 \times n_2+\frac{n_2 \times (n_2+1)}{2} - R_2\)
wobei, \(n_1\) und \(n_2\) die jeweiligen Stichprobenumfänge und \(R_1\) und \(R_2\) die Rangsummen der Gruppen 1 und 2 sind.
| Gruppe | Punkte | Rang |
|---|---|---|
| INT | 99 | 1 |
| INT | 96 | 2 |
| CON | 95 | 3 |
| INT | 94 | 4 |
| CON | 93 | 5 |
| INT | 92 | 6 |
| INT | 91 | 7 |
| INT | 90 | 8 |
| INT | 89 | 9 |
| CON | 88 | 10 |
| INT | 84 | 11 |
| CON | 81 | 12 |
| CON | 80 | 13 |
| CON | 75 | 14 |
| CON | 72 | 15 |
| Gruppe | Rangsumme |
|---|---|
| CON | 72 |
| INT | 48 |
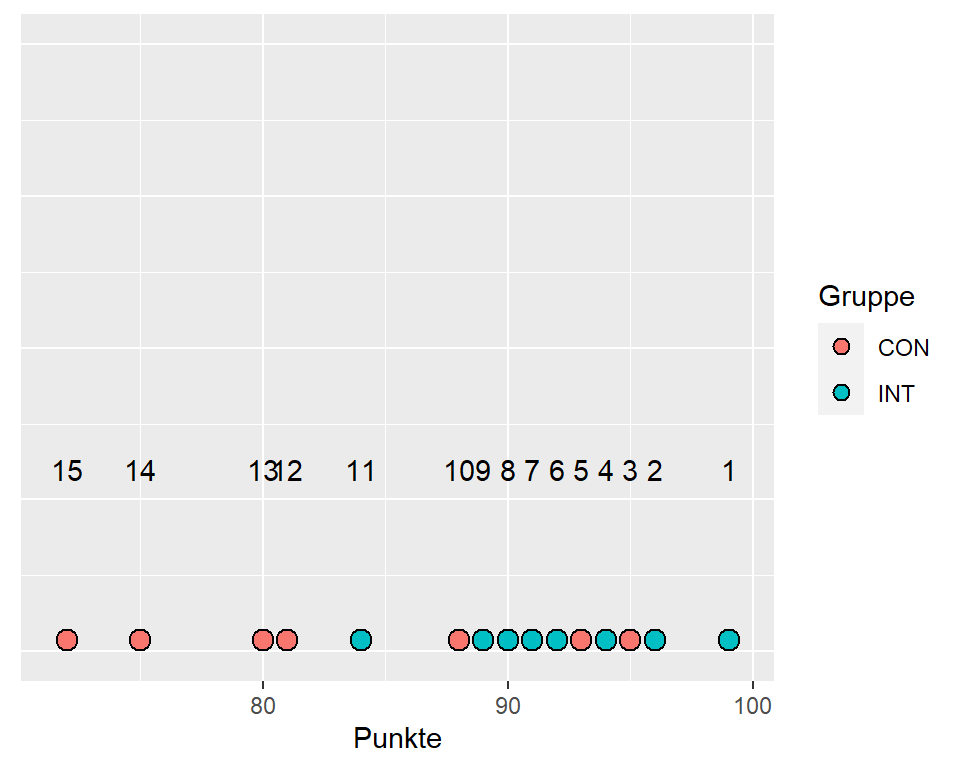
Abbildung 6.10: Punktediagramm der Ränge für Statistikresultate
Berechnung der Teststatistiken \(U_1\) für die Interventionsgruppe und \(U_2\) für die Kontrollgruppe
\(U_1 = 8\times7+\frac{8(8+1)}{2} - 48 = 44\)
\(U_2 = 8\times7+\frac{7(7+1)}{2} - 72 = 12\)
Unsere Teststatistik \(U\) ist die kleinere der beiden Grössen \(U_1\) und \(U_2\): \(U = 12\)
Berechnung des p-Werts mit R
### R-Code
U <- 12
p_Wert <- 2 * (1 - pwilcox(U, m = 8, n = 7, lower.tail = FALSE))
p_Wert## [1] 0.07210567Da der p-Wert mit 0.0721 grösser als \(\alpha = 0.05\) verwerfen wir die Nullhypothese nicht.
Schlussfolgerung: Untersucht wurde die Frage, ob Studierende, die während einer Woche täglich 30 Minuten Statistikübungen machen, bessere Punktzahlen erreichen als Studierende, die das nicht tun. Studierende, die während einer Woche täglich 30 Minunten Statistikübungen machen, erreichten in unserer Studie im Durchschnitt eine um 8.45 Punkte höhere Punktzahl in der Statistikprüfung, Mann-Whitney-U = 12, p = 0.0721. Damit liegt keine Evidenz dafür vor, dass sich die Prüfungsergebnisse im Durchschnitt zwischen den beiden Gruppen unterscheiden.
6.7.3.1 R/jamovi
R Code und Output
### R-Code
wilcox.test(
Punkte ~ Gruppe, data = statex,
paired = FALSE,
alternative = "two.sided")##
## Wilcoxon rank sum exact test
##
## data: Punkte by Gruppe
## W = 12, p-value = 0.07211
## alternative hypothesis: true location shift is not equal to 0jamovi-Output
jamovi\T-Tests\Independent Samples T-Test\Mann-Whitney U

jamovi-Output Mann Whitney U-Test
6.7.3.2 Voraussetzungen für den Mann-Whitney-U-Test:
- Die Daten sind mindestens qualitativ-ordinal skaliert (Likert-Skalen, visuelle Analogskalen).
- Es müssen zwei unabhängige Zufallsstichproben vorliegen.
- Die Daten sollten gleich verteilt sein (z.B. beide linksschief)
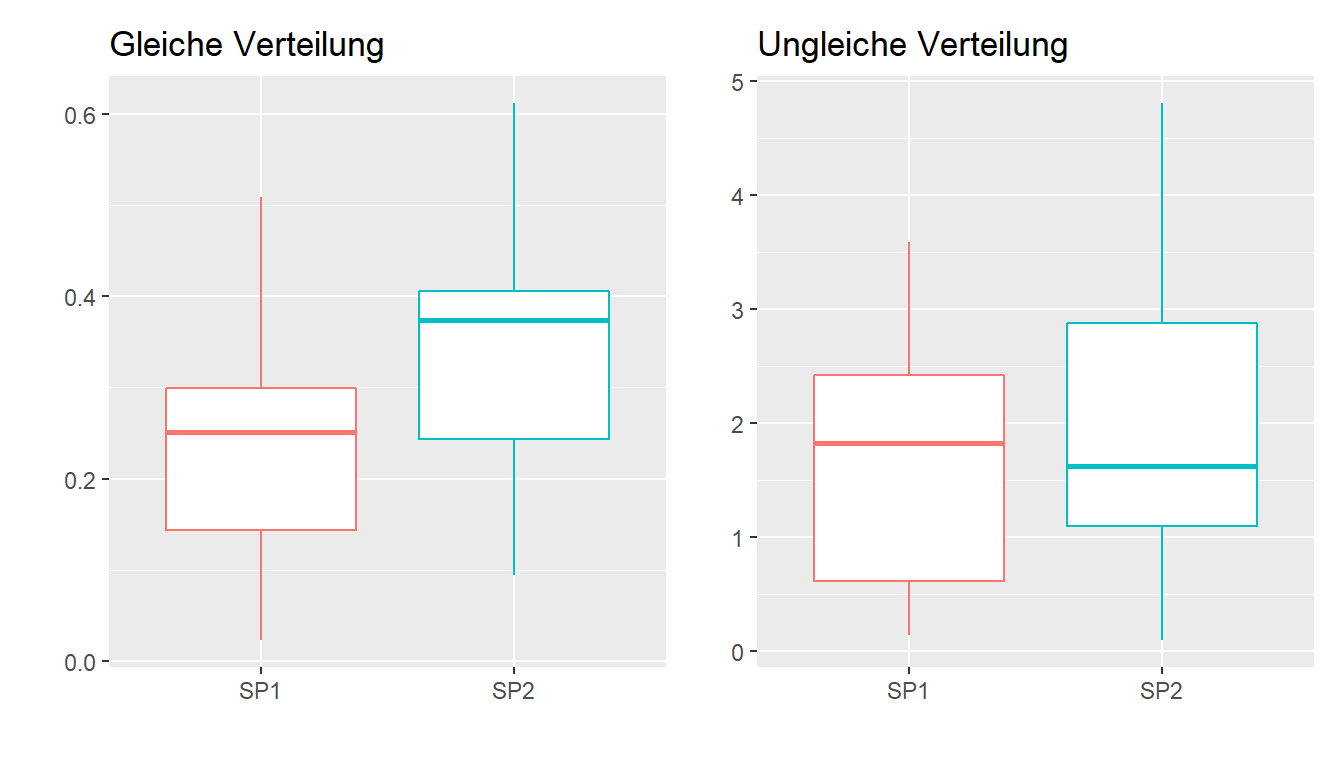
Abbildung 6.11: Gleiche versus ungleiche Verteilung
| Stichprobe | M | Median |
|---|---|---|
| SP1 | 0.24 | 0.25 |
| SP2 | 0.34 | 0.37 |
| Stichprobe | M | Median |
|---|---|---|
| SP1 | 1.59 | 1.83 |
| SP2 | 1.99 | 1.62 |
Boxplot und Kennzahlen beider Stichproben in der Abbildung links zeigen eine linksschiefe Verteilung. Die Daten in der rechten Abbildung zeigen für die Gruppe SP1 eine linksschiefe und für die Stichprobe SP2 eine rechtsschiefe Verteilung.
Übung: Im Beispiel für den t-Test für unabhängige Stichproben haben wir festgestellt, dass die Daten nicht aus einer normalverteilten Population stammen und die korrekte Testwahl wäre der Mann-Whitney-U-Test. Führen Sie diesen durch und vergleichen Sie das Resultat mit dem t-Test für unabhängige Stichproben.