7 Korrelation und linearer Zusammenhang
7.1 Einleitung
In diesem Kapitel beschäftigen wir uns mit Zusammenhängen zwischen Variablen. Beispiele für Zusammenhänge von Variablen aus dem Alltag sind:
- Je länger jemand joggt, desto grösser ist sein Kalorienverbrauch.
- Je weniger Geld ich für die Werbung für meine Firma ausgebe, desto weniger Kunden habe ich.
- Je höher die Aussentemperatur ist, desto mehr Eis verkaufen die Eisstände.
- Je öfter es regnet, desto teurer werden die Regenschirmpreise.
- Je mehr Zeit jemand ins Krafttraining investiert, desto stärker wird er.
- Je schneller ein Zug fährt, desto kürzer wird die Reisezeit.
- Je länger der Winter dauert, desto höher werden die Heizkosten.
Den linearen Zusammenhang zwischen zwei Variablen bezeichnen wir als Korrelation. Wenn man die Beziehung zwischen zwei Variablen kennt, können wir den Wert der einen Variablen verwenden um den Wert der anderen Variablen vorherzusagen.
7.2 Lernziele
- Beschreibe die Eigenschaften des Zusammenhangs von zwei Variablen mit folgenden Begriffen
- Richtung: Ein positiver Zusammenhang besteht dann, wenn sich bei einer Erhöhung von x auch y erhöht; wenn sich bei einer Erniedrigung von x der Wert von y erhöht, sprechen wir von einem negativen Zusammenhang.
- Form: Ein Zusammenhang ist linear oder nicht-linear
- Stärke: Ein Zusammenhang ist stark, wenn die Streuung der Daten um die zugrundeliegende Beziehung gering ist und schwach, wenn die Streuung der Daten gross ist.
- Richtung: Ein positiver Zusammenhang besteht dann, wenn sich bei einer Erhöhung von x auch y erhöht; wenn sich bei einer Erniedrigung von x der Wert von y erhöht, sprechen wir von einem negativen Zusammenhang.
- Definiere eine Korrelation als lineare Beziehung zwischen zwei quantitativen Variablen.
- Beachte, dass der Korrelationskoeffizient \(r\) folgende Eigenschaften aufweist:
- der (absolute) Wert des Korrelationskoeffizienten misst die Stärke der linearen Beziehung zwischen zwei quantitativen Variablen.
- das Vorzeichen (+ oder -) des Korrelationskoeffizienten beschreibt die Richtung des Zusammenhangs.
- der Korrelationskoeffizient liegt immer zwischen -1 und 1. -1 bedeutet perfekter negativer linearer Zusammenhang, + 1 bedeutet perfekter positiver linearer Zusammenhang und 0 bedeutet kein linearer Zusammenhang.
- der Korrelationskoeffizient ist dimensionslos.
- der Korrelationskoeffizient von X mit Y ist der selbe wie von Y zu X.
- der Korrelationskoeffizient nach Pearson \(r\) ist empfindlich für Ausreisser.
- Der Rangkorrelationskoeffizient nach Spearman \(r_s\) misst den monotonen Zusammenhang und ist robust gegen Ausreisser.
- der (absolute) Wert des Korrelationskoeffizienten misst die Stärke der linearen Beziehung zwischen zwei quantitativen Variablen.
- Korrelation bedeutet nicht, dass ein ursächlicher Zusammenhang besteht! Correlation does not imply causation!
7.3 Korrelation
Eine Korrelation beschreibt eine Beziehung zwischen zwei oder mehreren quantitativen Merkmalen (Variablen). Dabei muss diese Beziehung nicht kausal sein, d.h. die Variablen müssen sich nicht gegenseitig beeinflussen und der Zusammenhang kann völlig zufällig sein.
Beispiel: Gibt es einen Zusammenhang zwischen der Laufgeschwindigkeit und dem Kalorienverbrauch pro Stunde? Wir verwenden die Stichprobendaten von \(n\) = 11 durchschnittlich 59 kg schweren Läuferinnen. (Datensatz 05_running2.csv)
| km/h | kCal/h |
|---|---|
| 8.0 | 472 |
| 8.4 | 531 |
| 9.7 | 590 |
| 10.8 | 649 |
| 11.3 | 679 |
| 12.1 | 738 |
| 12.9 | 797 |
| 13.9 | 826 |
| 14.5 | 885 |
| 16.1 | 944 |
| 17.5 | 1062 |
Der Tabelle entnehmen wir, dass mit zunehmender Laufgeschwindigkeit auch der Kalorienverbrauch zunimmt. Zusammenhänge zwischen zwei quantitativen Variablen können gut mit Hilfe eines Streudiagramms (engl. scatterplot) visualisiert werden.
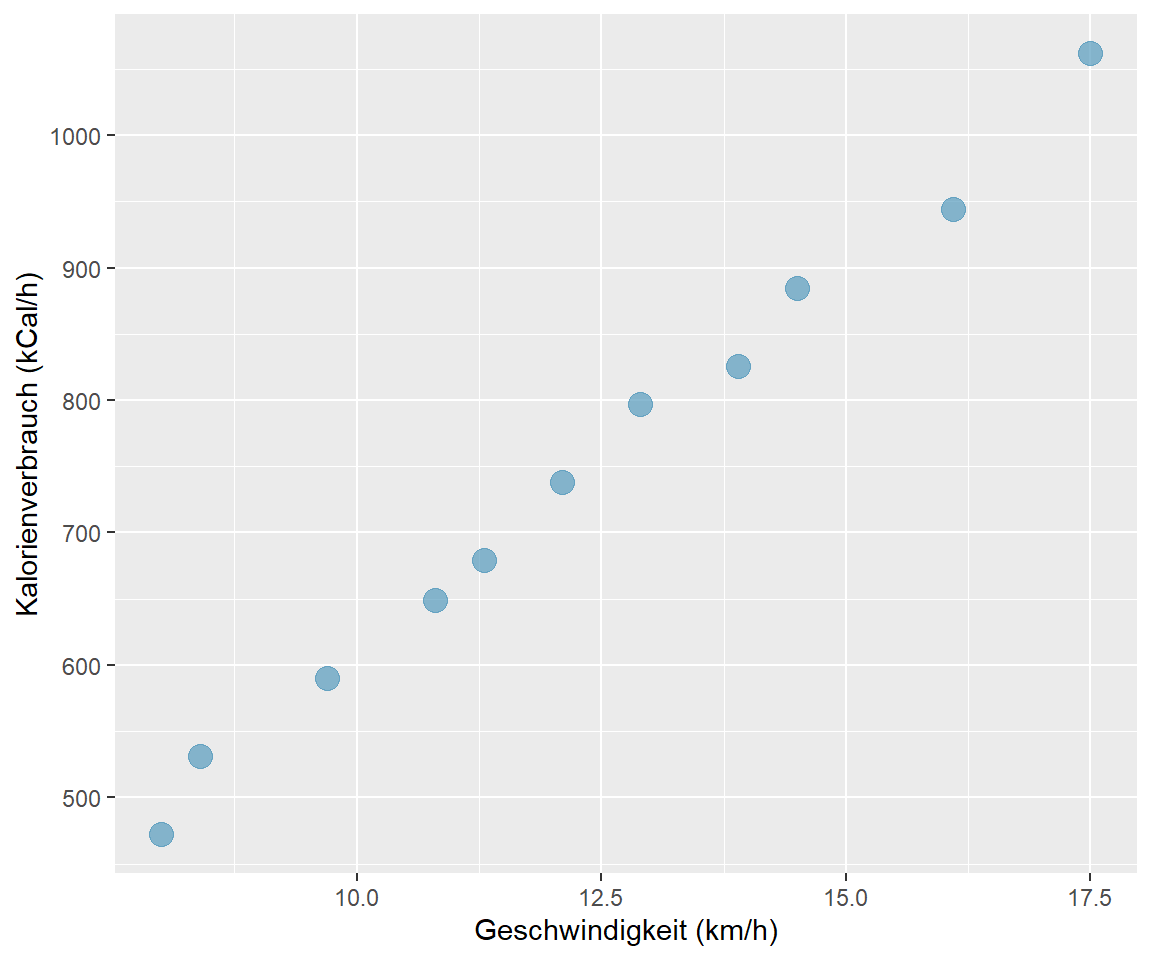
Abbildung 7.1: Kalorienverbrauch nach Laufgeschwindigkeit, n = 11
Jeder Punkt im Streudiagramm 7.1 repräsentiert eine Kombination von Geschwindigkeit (x-Achse) und Kalorienverbrauch (y-Achse). Wenn wir die Punkte visuell miteinander verbinden, entsteht eine - nicht ganz perfekte - Gerade. In diesem Fall sprechen wir von einem linearen Zusammenhang.
7.3.1 Eigenschaften von Zusammenhängen
Die folgenden acht Punktdiagramme zeigen verschiedene Zusammenhänge zwischen der X- und der Y-Variablen.
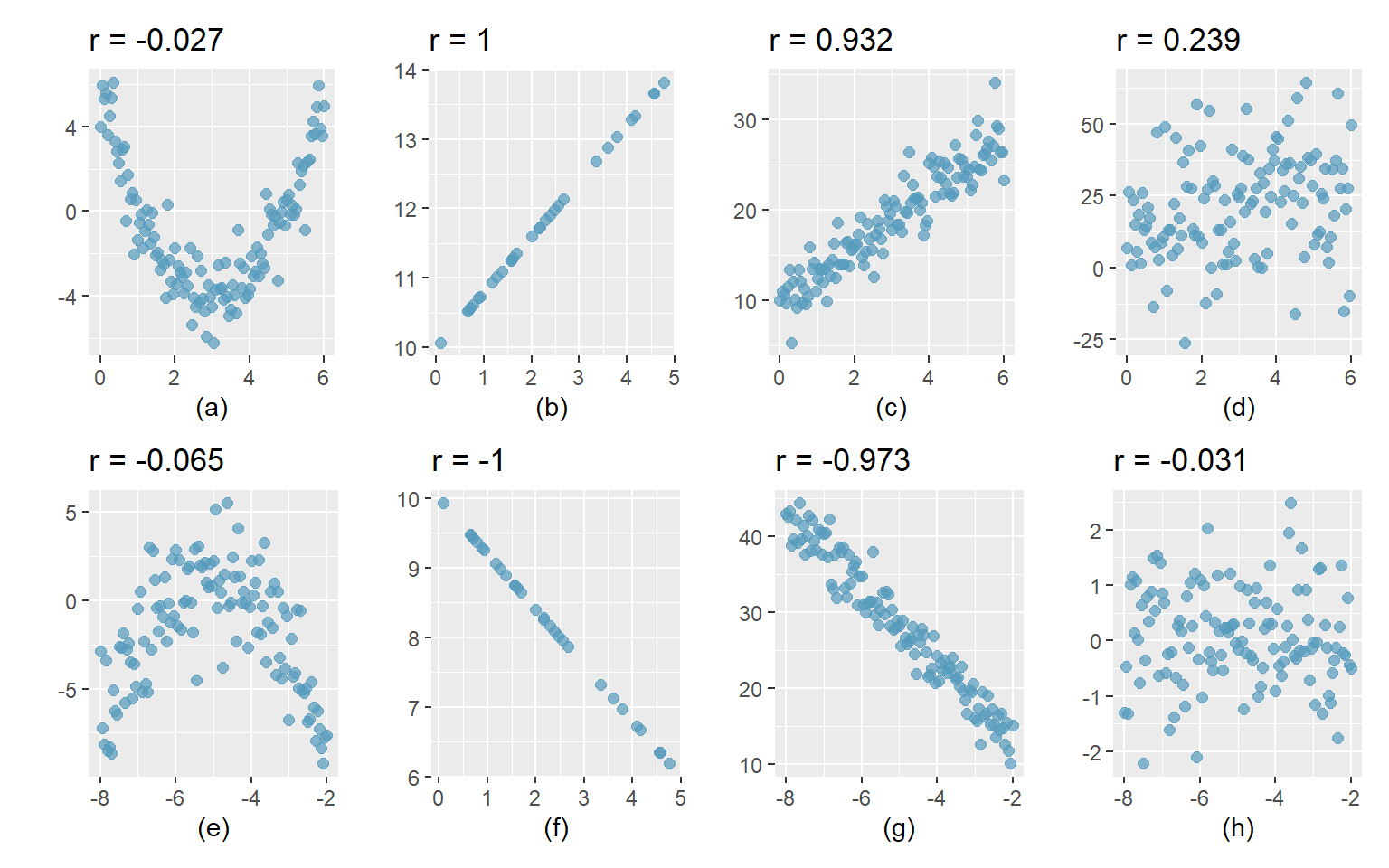
Abbildung 7.2: Zusammenhänge identifizieren
Interpretation:
- Starker nicht-linearer Zusammenhang zwischen X und Y.
- Perfekter positiver linearer Zusammenhang zwischen X und Y.
- Starker positiver linearer Zusammenhang zwischen X und Y:
- Wenn X grösser wird, wird auch Y grösser: positiver Zusammenhang.
- Die Punkte liegen etwa parallel zu einer gedachten Geraden: linearer Zusammenhang.
- Die Punkte streuen wenig um eine gedachte Linie: starker Zusammenhang.
- Wenn X grösser wird, wird auch Y grösser: positiver Zusammenhang.
- Schwacher positiver linearer Zusammenhang, die Punkte streuen stark.
- Moderater Zusammenhang zwischen X und Y, der Zusammenhang ist nicht-linear.
- Perfekter negativer linearer Zusammenhang.
- Starker negativer linearer Zusammenhang:
- Wenn X grösser wird, wird Y kleiner: negativer Zusammenhang
- Die Punkte liegen nahe bei einer gedachten Gerade: starker linearer Zusammenhang.
- Wenn X grösser wird, wird Y kleiner: negativer Zusammenhang
- Kein Zusammenhang zwischen X und Y.
7.3.2 Korrelationskoeffizient \(r\)
Der Korrelationskoeffizient nach Pearson \(r\) ist ein Mass dafür, wie stark der lineare Zusammenhang zwischen zwei Variablen ist. Stehen zwei Variablen miteinander in Zusammenhang, kann man Aussagen darüber treffen, wie sich die Werte der einen Variable verhalten, wenn die Werte der anderen Variable ansteigen oder abfallen.
Interpretation von \(r\)
- Der Korrelationskoeffizient \(r\) kann Werte zwischen -1 und 1 annehmen. Je näher \(r\) bei 1 (bzw. bei -1) liegt, desto stärker ist der Zusammenhang der Variablen. Bei \(r\) = 1 liegen alle Punkte der Daten auf einer steigenden Geraden; entsprechend bei -1 auf einer fallenden Geraden.
- \(r > 0\): Ist der Korrelationskoeffizient grösser als null, liegt eine positive Korrelation vor: Je grösser die Werte der einen Variablen, desto grösser sind die Werte der anderen Variablen.
- \(r < 0\): Ist der Korrelationskoeffizient kleiner als null, liegt eine negative Korrelation vor: Je grösser die Werte der einen Variablen, desto kleiner sind die Werte der anderen Variablen.
- \(r \approx 0\): Liegt der Korrelationskoeffizient nahe 0, gibt es keinen linearen Zusammenhang zwischen den Variablen. Es ist keine Aussage darüber möglich, wie sich die Werte der einen Variablen verändern, wenn die Werte der anderen Variablen steigen oder sinken.
- Beachte, dass der Korrelationskoeffizient nur lineare Zusammenhänge abbildet. Es kann sein, dass die Variablen zusammenhängen, nur eben nicht linear, z.B. quadratisch oder exponentiell. Ein Korrelationskoeffizient nahe bei 0 bedeutet daher nicht, dass überhaupt kein Zusammenhang besteht. Es bedeutet nur, dass kein linearer Zusammenhang besteht.
Als Faustregel für die Beurteilung der Stärke einer Korrelation kann man sich an folgender Tabelle orientieren:
| Korrelation | Stärke | Richtung |
|---|---|---|
| -1.0 to -0.8 | stark | Negativ |
| -0.8 to -0.5 | moderat | Negativ |
| -0.5 to 0 | schwach | Negativ |
| 0 to 0.5 | schwach | Positiv |
| 0.5 to 0.8 | moderat | Positiv |
| 0.8 to 1.0 | stark | Positiv |
7.3.3 Berechnung von \(r\)
Der Korrelationskoeffizient nach Pearson wird berechnet nach der Formel
\[r = \frac{1}{n-1}\sum_{i=1}^n \lgroup \frac{x_i-\bar{x}}{s_x} \rgroup \lgroup \frac{y_i - \bar{y}}{s_y} \rgroup\]
\((x_1, y_1), (x_2, y_2),..., (x_n, y_n)\) sind die \(n\) Datenpaare für \(x\) und \(y\) und \(s_x\) und \(s_y\) sind die Standardabweichungen von \(x\) und \(y\) in der Stichprobe.
Wir lernen das nicht und ersparen uns die Berechnung von Korrelationskoeffizienten von Hand (aber die Formel finde ich trotzdem cool). Das übernimmt die Statistiksoftware.
Die Funktion in R (R Core Team 2022) für die Berechnung des Korrelationskoeffizienten ist
### R-Code
# Korrelationskoeffizient nach Pearson
cor(x, y) 7.3.4 Hypothesentest für \(r\)
Auch für den Korrelationskoeffizienten exisitiert ein Hypothesentest. Wie bei jedem Hypothesentest wird auch hier aus Stichprobendaten auf die Population, aus der die Stichprobe stammt, geschlossen. Für den Korrelationskoeffizienten nach Pearson \(r\) lauten die Hypothesen:
\(H_0: \rho = 0\) Es besteht kein linearer Zusammenhang zwischen zwei Variablen.
\(H_A: \rho \neq 0\) Es besteht ein linearer Zusammenhnag zwischen zwei Variablen.
\(\rho\) (gr. Rho) ist der Korrelationskoeffizient auf Populationsebene.
Die Funktion in R für diesen Hypothesentest ist
### R-Code
# Hypothesentest für r
cor.test(x, y)7.3.5 Interpretation des Beispiels für Laufgeschwindigkeit und Kalorienverbrauch
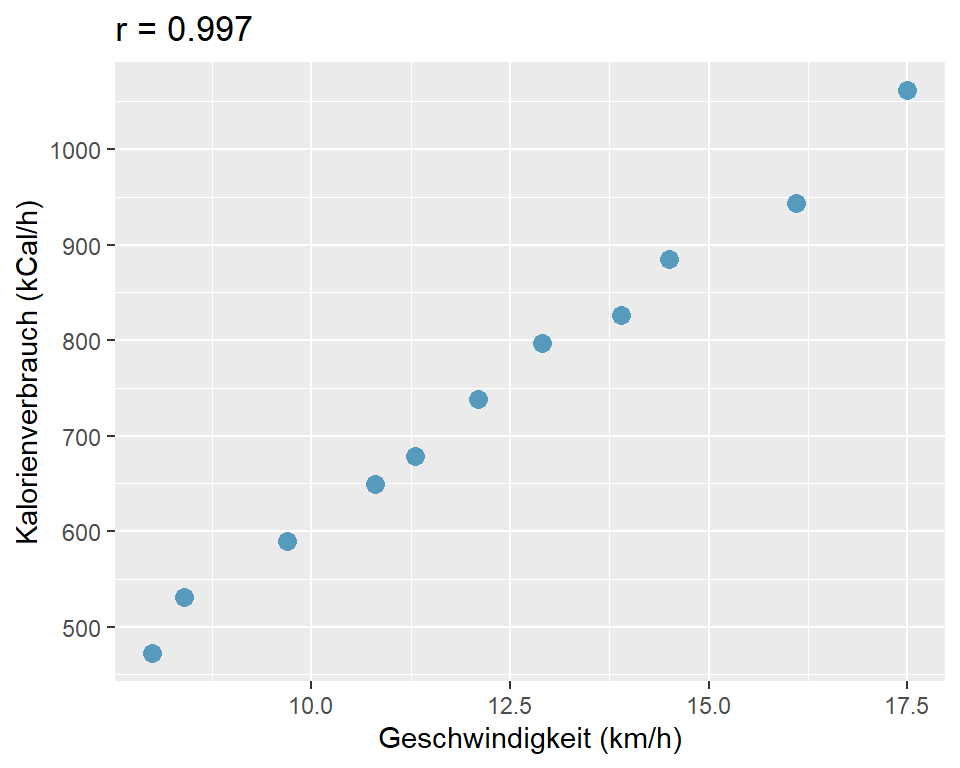
Abbildung 7.3: Zusammenhang von Kalorienverbrauch und Laufgeschwindigkeit
Wir sehen, dass eine starke positive lineare Korrelation zwischen der Laufgeschwindigkeit und dem Kalorienverbrauch besteht. Der Korrelationskoeffizient nach Pearson \(r\) ist 0.997.
### R-Code
cor.test(running$kmh, running$kg59)##
## Pearson's product-moment correlation
##
## data: running$kmh and running$kg59
## t = 37.892, df = 9, p-value = 3.082e-11
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.9875851 0.9992189
## sample estimates:
## cor
## 0.9968805Der Hypothesentest in Rergibt einen p-Wert von \(3.082 \times 10^{-11}\). Dies ist ein extrem kleiner p-Wert, der unter dem üblichen Signifikanzniveau von \(\alpha = 0.05\) liegt. Wir schliessen daraus, dass wir die Nullhypothese zugunsten der Alternativhypothese verwerfen können und dass ein statistisch signifikanter Zusammenhang zwischen Laufgeschwindigkeit und Kalorienverbrauch besteht.
Die Stichprobendaten liefern Evidenz dafür, dass ein nahezu perfekter positiver linearer Zusammenhang zwischen Laufgeschwindigkeit und Kalorienverbrauch in der Population (59kg schwere Frauen) besteht, \(r\) = 0.997 [0.988; 0.999], p < 0.001.
7.3.6 Datenmuster und \(r\)
Korrelationskoeffizienten sind unter Forscher:innen beliebt, weil sie den Zusammenhang zwischen zwei Variablen in einer einzigen Zahl zusammenfassen. Allerdings kann ein bestimmter Korrelationskoeffizient eine Vielzahl von Mustern zwischen zwei Variablen repräsentieren und ohne zusätzliche Information - idealerweise in Form eines Streudiagramms - wissen weder die Forscher:innen noch die Leser:innen, um welche Art von Zusammenhang es sich handelt.
Die folgenden 16 Streudiagramme zeigen, was sich alles hinter einem Korrelationskoeffizienten von \(r = 0.8\) (n = 50) verbergen kann. (Quelle und Erläuterungen: https://janhove.github.io/teaching/2016/11/21/what-correlations-look-like)
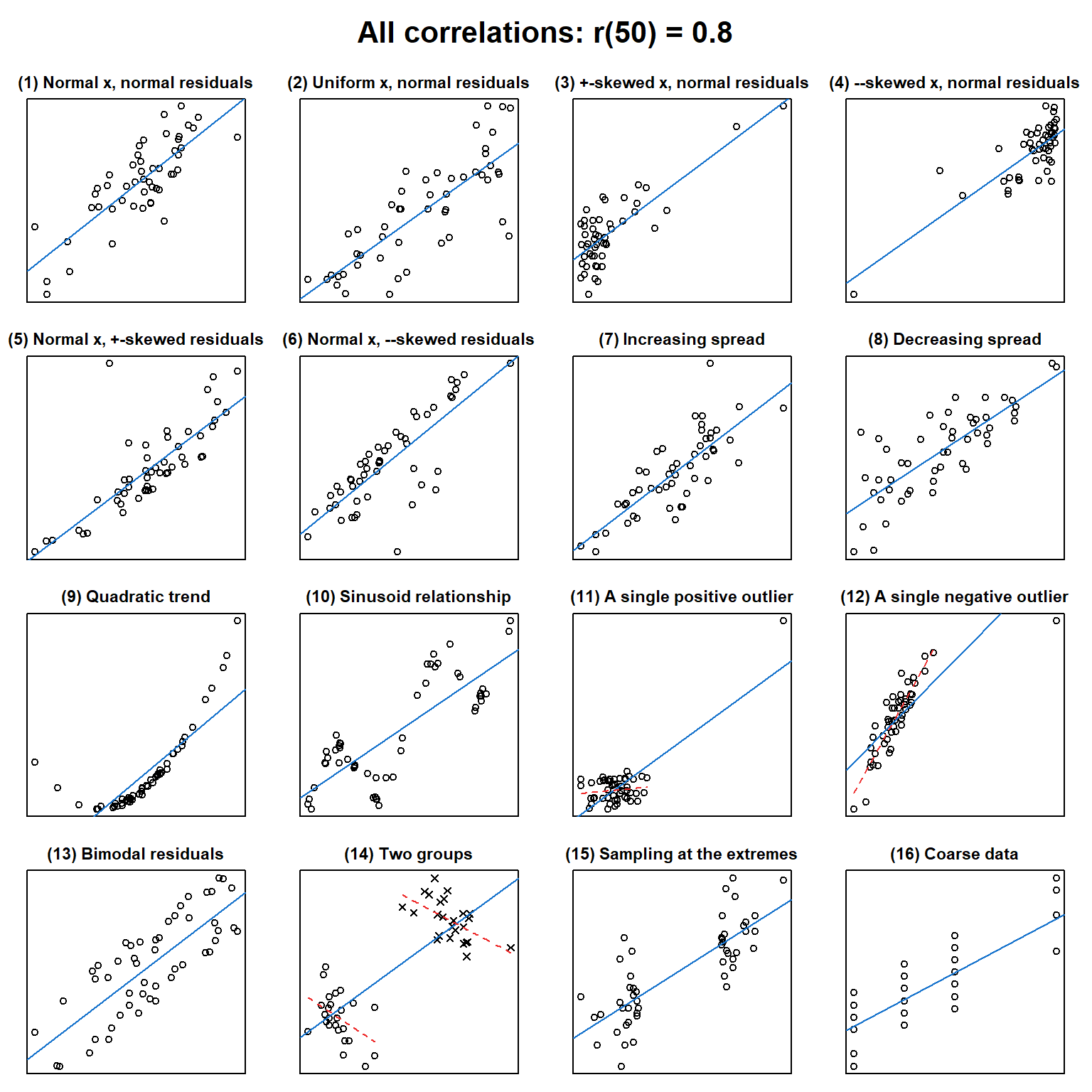
Abbildung 7.4: 16 Varianten von Zusammenhängen, alle \(r\) = 0.8
Ohne im einzelnen auf die Streudiagramme in Abbildung 7.4 einzugehen, ist leicht zu erkennen, dass ganz unterschiedliche Muster des Zusammenhangs zwischen zwei Variablen mit dem gleichen Korrelationskoeffizienten \(r\) vorhanden sein können.
Betrachten wir das Beispiel 12 aus der Abbildung 7.4 etwas genauer:
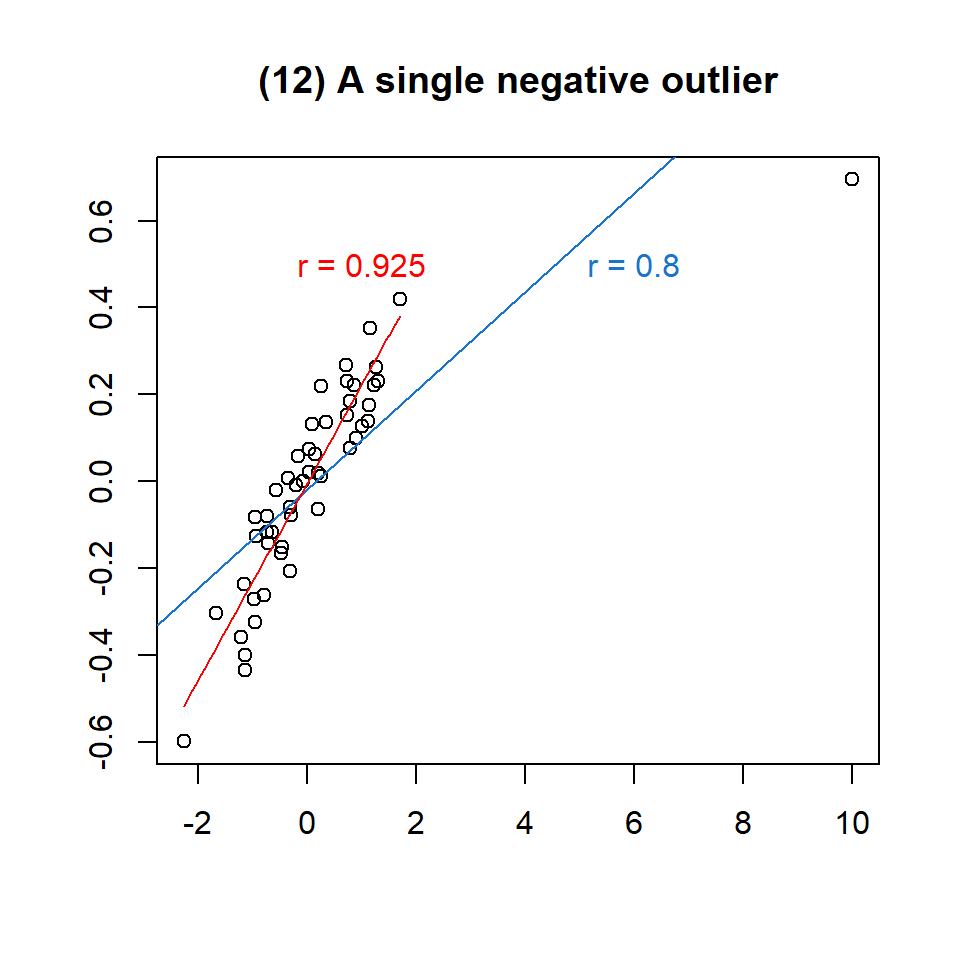
Abbildung 7.5: Einfluss eines Ausreissers auf \(r\)
Wir sehen links zwischen x = -2.3 und x = 1.8 eine Punktewolke, die einen starken positiven linearen Zusammenhang zwischen x und y zeigt. Bei x = 10, y = 6.2 befindet sich ein Ausreisser. Der Korrelationskoeffizient für alle Daten beträgt \(r = 0.8\). Wenn wir den Ausreisser entfernen, erhöht sich der Korrelationskoeffizient auf \(r = 0.925\), was vermutlich eher dem wahren Zusammenhang zwischen den Variablen entspricht. Unsere Schlussfolgerung: Der Korrelationskoeffizient nach Pearson \(r\) ist empfindlich für Extremwerte!
7.3.7 Rangkorrelationskoeffizient nach Spearman
Der Rangkorrelationskoeffizient nach Spearman \(r_s\) ist ähnlich wie der Korrelationskoeffizient nach Pearson \(r\) eine Methode, um Zusammenhänge zwischen Variablen zu quantifizieren. Dabei handelt es sich um einen nicht-parametrischen Test, bei dem die Korrelation anhand zuvor vergebener Ränge berechnet wird. Der Vorteil des Rangkorrelationskoeffizienten nach Spearman ist, dass er robust gegen Ausreisser ist und - in gewissem Umfang - auch nicht-lineare Zusammenhänge beschreiben kann. Die Interpretation von \(r_S\) ist genau gleich, wie für \(r\).
Der Rangkorrelationskoeffizient nach Spearman \(r_s\) quantifiziert den monotonen Zusammenhang der Variablen und nicht den linearen Zusammenhang. Monotoner Zusammenhang bedeutet, wenn X steigt, steigt Y in der Tendenz auch bzw. wenn X steigt, sinkt Y in der Tendenz.
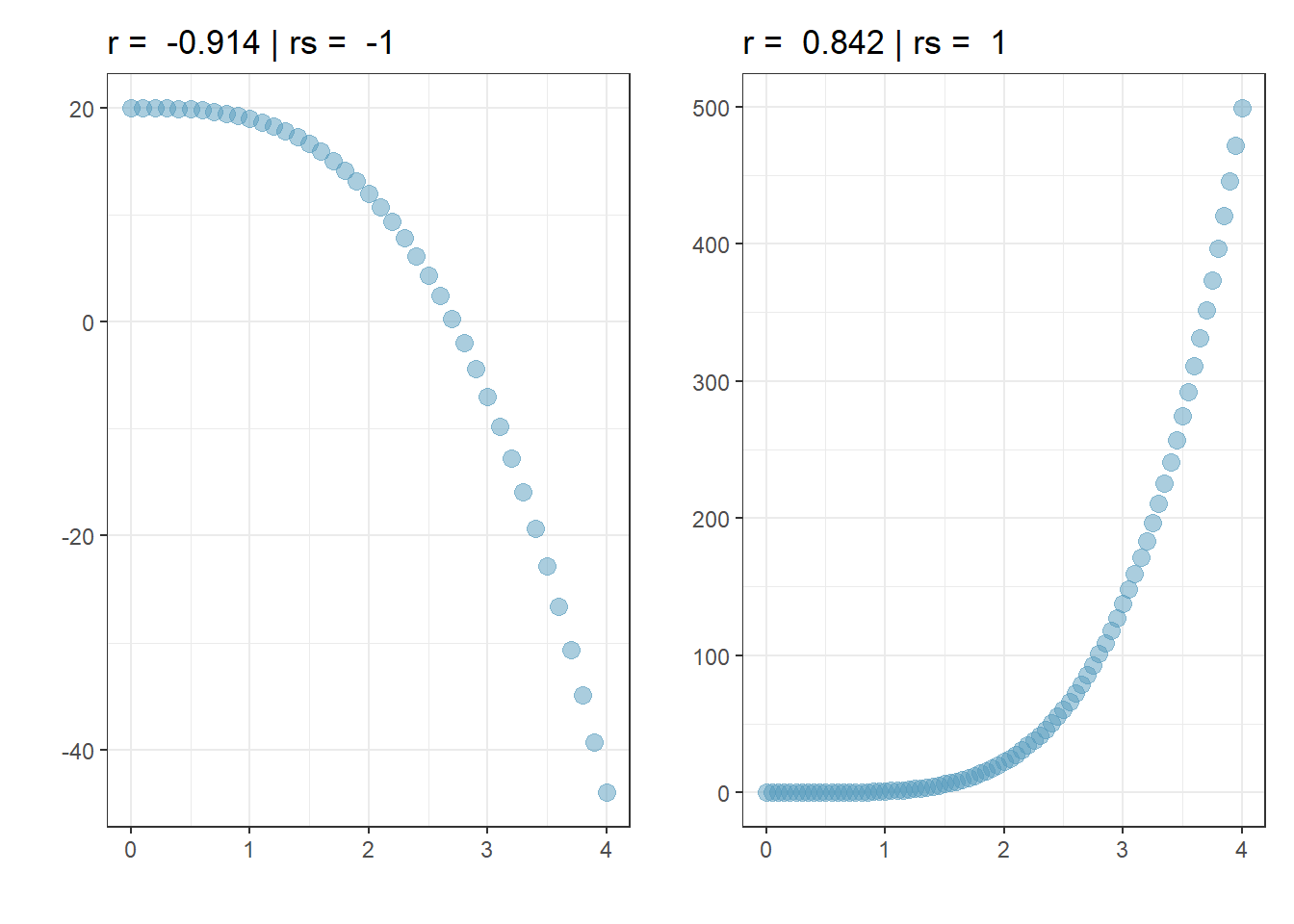
Abbildung 7.6: Zwei perfekte monotone Zusammenhänge
Die Funktion in R für die Berechnung von \(r_S\) ist
### R-Code
# Rangkorrelationskoeffizient nach Spearman
cor(x, y, method = "spearman")Die Berechnung von \(r_s\) für das Beispiel 12 (alle Daten inkl. Ausreisser) ergibt \(r_S = 0.938\). Der Wert von \(r_s\) liegt nahe am Wert für \(r = 0.925\) für die Daten ohne den Ausreisser.
7.3.8 Scheinkorrelationen
Das folgende Beispiel soll zeigen, dass bei der Interpretation von Korrelationen Vorsicht geboten ist.
Frage: Besteht ein Zusammenhang zwischen der Schuhgrösse und dem Einkommen?
Wir überprüfen diese Frage anhand der Angaben einer Stichprobe von \(n\) = 1000. Die Proband:innen wurden nach ihrer Schuhgrösse (nur ganze Grössen) und ihrem monatlichen Bruttoeinkommen befragt. (Datensatz 05_shoesize.csv)
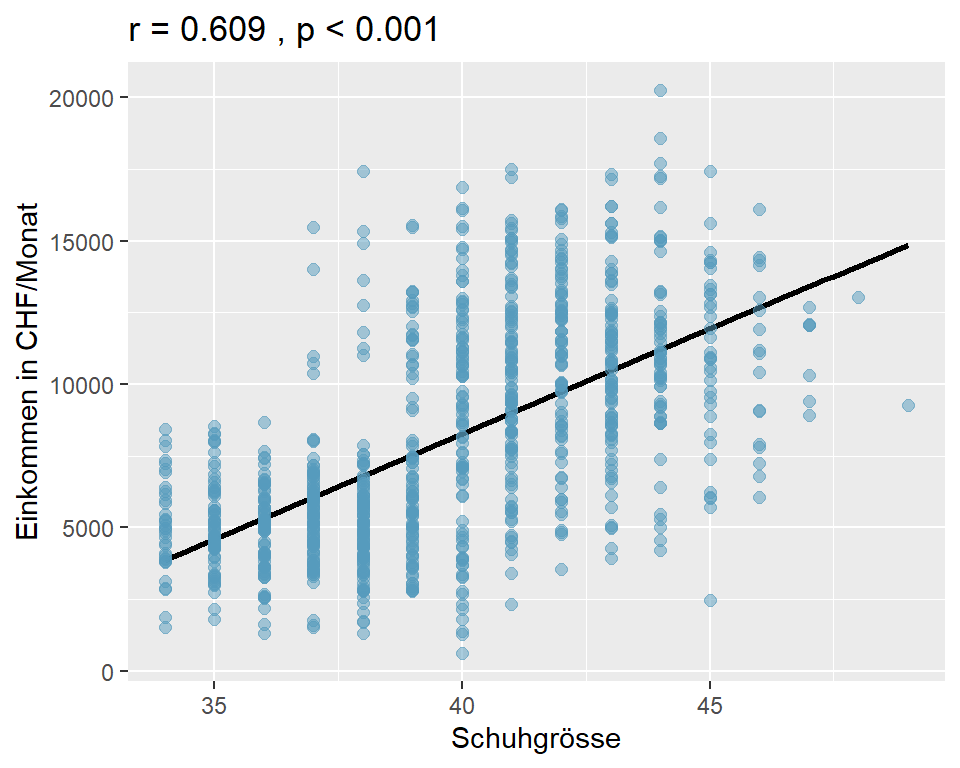
Abbildung 7.7: Einkommen nach Schuhgrösse, n = 1000
Die Analyse ergibt einen moderaten positiven linearen Zusammenhang zwischen der Schuhgrösse und dem monatlichen Einkommen; mit zunehmender Schuhgrösse nimmt auch das monatliche Bruttoeinkommen zu (\(r\) = 0.609, p < 0.001).
Aber ist diese Schlussfolgerung auch korrekt oder haben wir etwas übersehen?
Die Analyse der Daten nach Geschlecht getrennt ergibt folgendes Resultat:
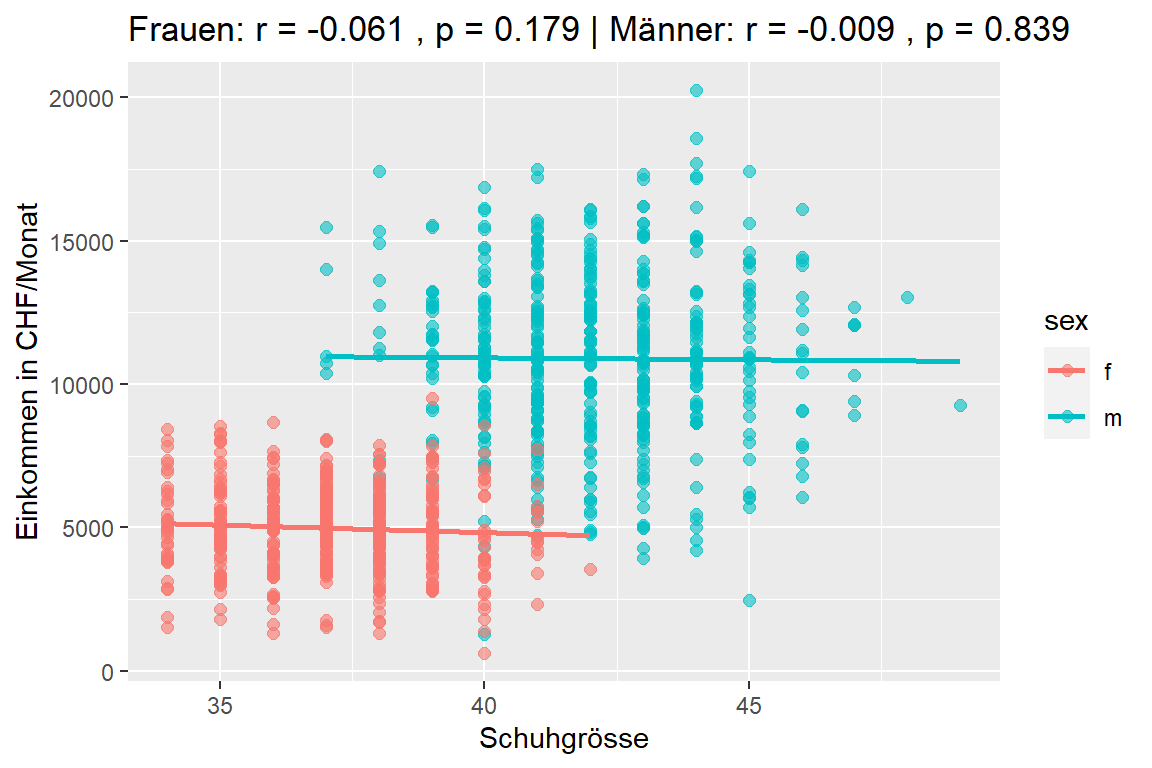
Abbildung 7.8: Einkommen nach Schuhgrösse
Wenn wir die Daten nach Geschlecht getrennt analysieren, verschwindet der Effekt vollständig. Wir haben keine Evidenz mehr dafür, dass ein Zusammenhang zwischen Schuhgrösse und Einkommen besteht (Frauen \(r\) = -0.061, p = 0.179; Männer \(r\) = -0.009, p = 0.839).
Wie können wir dieses Ergebnis interpretieren? Männer haben typischerweise eine grössere Schuhgrösse als Frauen. Zudem haben Männer im Durchschnitt - nach wie vor - ein höheres Einkommen als Frauen. Es ist demnach das Geschlecht, das einen Einfluss auf das Einkommen hat, denn wir wissen intuitiv, dass die Schuhgrösse definitiv nichts mit dem Einkommen zu tun haben kann. In diesem Fall sprechen wir von einer Scheinkorrelation, die einen Zusammenhang feststellt, wo - zumindest kausal - keiner vorhanden ist. Das Geschlecht ist im vorliegenden Fall ein Störfaktor (engl. confounder), der sowohl das Einkommen als auch die Schuhgrösse bestimmt.
Unter Confounding versteht man eine systematische Verzerrung, hervorgerufen durch einen oder mehrere Störfaktoren, die mit beiden Variablen zusammenhängen und bei der Untersuchung nicht berücksichtigt werden.
Weitere Beispiele für Scheinkorrelationen findet man in diesem Video unter diesem Link.
7.4 Zusammenfassung
- Pearson’s Korrelationskoeffizient ist für viele Dinge nützlich, hat aber den Nachteil, dass er nur die Stärke einer linearen Korrelation zwischen zwei Variablen messen kann. Mit anderen Worten misst er, in welchem Mass die Daten auf eine perfekte gerade Linie fallen. Er ist empfindlich gegenüber Ausreissern.
- Für Variablen, deren Zusammenhang nicht linear ist (was man am besten an einem Streudiagramm beurteilt), eignet sich der Rangkorrelationskoeffizient nach Spearman besser. Er ist in der Lage, nicht-lineare Zusammenhänge zu messen und er ist robust gegen Ausreisser.
- Aus den 16 Grafiken haben wir gelernt, dass ein Zusammenhang zwischen zwei Variablen immer zuerst visuell am Streudiagramm und erst in zweiter Linie anhand des Korrelationskoeffizienten beurteilt werden muss!
7.5 Korrelation in R/jamovi
7.5.1 R Code und Output
Pearsons’s Korrelationskoeffizient
### R-Code
# Simulierte Daten
x <- c(-2, -1.5, -.5, 0, 1, 3, 4)
y <- c(5, 4.5, 6, 5.5, 6, 6.5, 7.5)
# Streudiagramm erstellen
plot(x, y)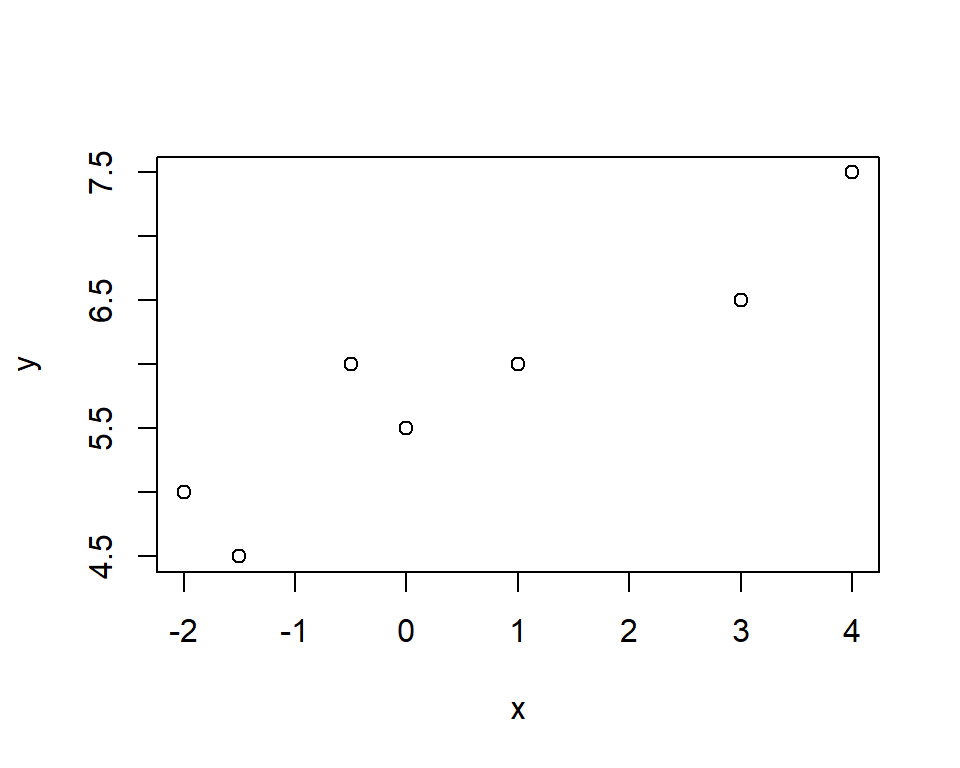
# Pearson's Korrelationskoeffizient
cor(x, y)## [1] 0.9262154# Hypothesentest für Pearson's Korrelationskoeffizient
cor.test(x, y)##
## Pearson's product-moment correlation
##
## data: x and y
## t = 5.4937, df = 5, p-value = 0.002729
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.5724094 0.9892662
## sample estimates:
## cor
## 0.9262154Rangkorrelationskoeffizient nach Spearman
### R-Code
# Simulierte Daten
x <- c(-2, -1.5, -.5, 0, 1, 3, 4)
y <- c(5, 4.5, 6, 5.5, 6, 6.5, 7.5)
# Streudiagramm erstellen
plot(x, y)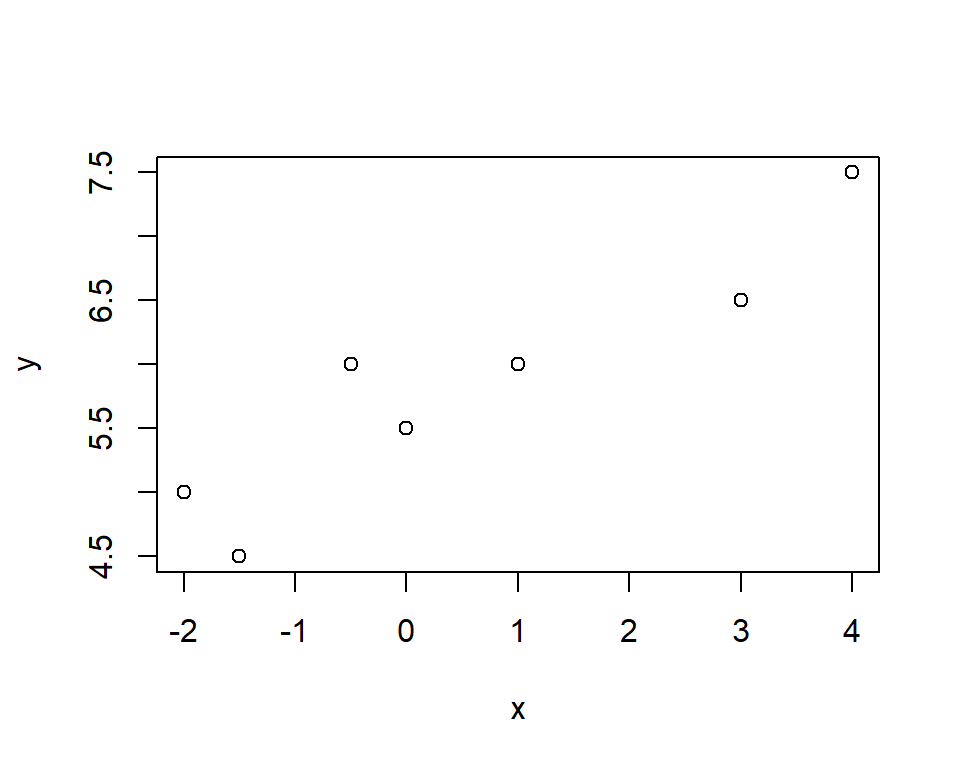
# Rangkorrelationskoeffizient nach Spearman
cor(x, y, method = "spearman")## [1] 0.9009375# Hypothesentest für Rangkorrelationskoeffizienten nach Spearman
cor.test(x, y, method = "spearman")##
## Spearman's rank correlation rho
##
## data: x and y
## S = 5.5475, p-value = 0.005621
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.90093757.5.2 jamovi Output
jamovi\..\Regression\Correlation Matrix
Pearson’s Korrelationskoeffizient
Im Menü unter Additional Options > Report significance und Confidence intervals wählen.
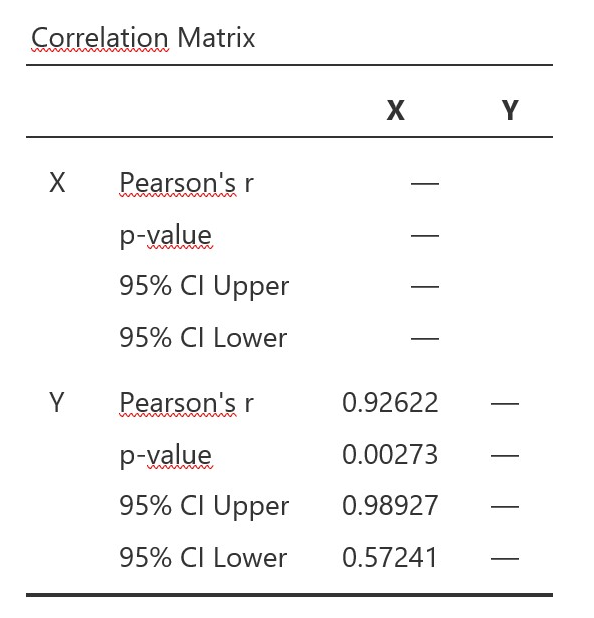
jamovi-Output Pearson
Rangkorrelationskoeffizient nach Spearman
Im Menü unter Correlation Coefficients > Spearman und unter Additional Options > Report significance wählen. Es kann kein Vertrauensintervall für \(r_s\) berechnet werden.
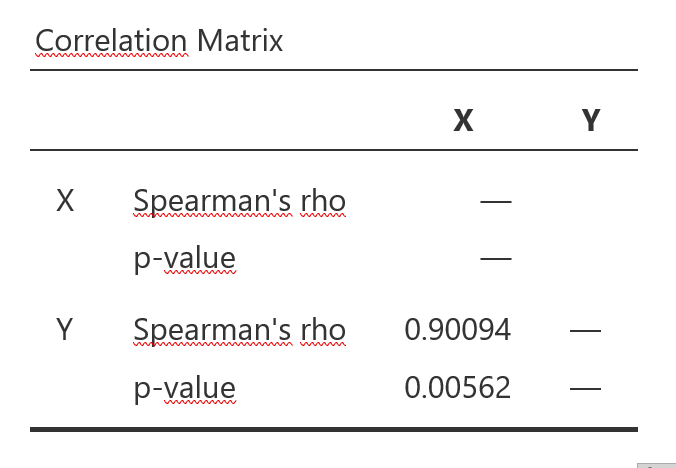
jamovi-Output Spearman